In this issue of #InfocusAI you’ll find information about China’s success in the global AI race, the influence of GPT-4 on the creation of biological threats, new records of open-source LLMs and initiatives to label AI-generated pictures in social networks. It would also prove useful to learn about Apple’s recommendations for efficient use of resources when developing AI models.
AI-focused digest – News from the AI world
Issue 35, January 25 – February 8, 2024
China approves 14 more LLMs and AI apps
In the last week of January, Chinese authorities approved one more batch of domestic AI models for public use. The batch includes 14 LLMs and generative technology-based enterprise AI applications, including a range of industry-specific ones, South China Morning Post reports. The latter comprise models focused on supporting consumer product producers, addressing information security challenges and various advertising, education, media and e-commerce tasks. The practice of approving generative AI models and AI-based solutions for public use has been in effect in China since August 2023. Reuters says that in six months, more than 40 AI models have passed state approval in China, including the latest batch.
OpenAI assesses the risks of using GPT-4 to create biological threats
According to the results of a large-scale experiment, experts at OpenAI have concluded that GPT-4 only slightly increases the ability of malicious actors to create biological threats. However, this risk is worth extra attention and proactive measures, as technology is evolving rapidly. To assess how dangerous GPT-4 could be in the wrong hands, the company enlisted 50 biology experts and 50 biology students in an experiment. The participants were divided into two groups. The participants of one of these groups were asked to complete some tasks to create a biological threat using only the Internet and with no access to AI. Individuals from the second group were free to use GPT-4 for this purpose. It turned out that the involvement of the LLM had only a marginal effect on the participants’ performance. The performance of the group using the GPT-4 was only slightly better than that of the first group. Read more about the experiment and its conclusions here.
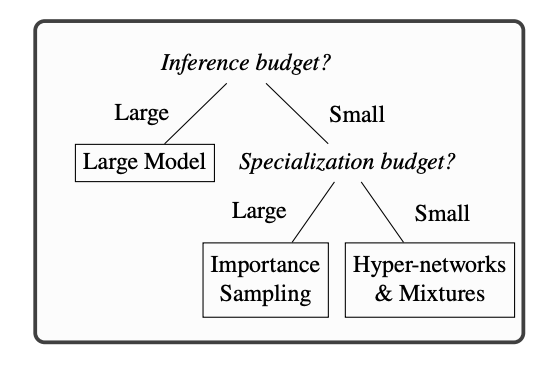
Apple presents recommendations for effective development of AI models with limited resources
Researchers at Apple recently published a paper in which they shared their vision on effective use of budget, or rather computational resources, for training AI models. First, scientists outlined four main parameters that affect the performance and cost of the models: the pretraining budget (for training before the target domain is known), the specialization budget (for training for a specific domain), the inference budget, and the in-domain training set size. Then, given the variables above, they explored and analysed different approaches to model training: hyper-networks, distillation, mixture of experts and importance sampling. As a result, the experts were able to form Apple-esque minimalistic recommendations for choosing the most appropriate methodology: if the specialisation budget is large (plenty of computational resources), pre-training with importance sampling is better, and if the budget is smaller, it is worth investing in hypernets and mixtures of experts. All of the findings fit into this infographic (taken from the study):
Social media users will be able to distinguish AI-generated images from real photos
Meta Platforms Inc. (recognised as extremist and banned in the Russian Federation) is planning to start labelling images created with other companies’ AI services, including those from OpenAI, Google, Microsoft, Adobe, Midjourney and Shutterstock, in its social networks. The pictures generated by its own AI are already being labelled by the company, Reuters reports. The need is long overdue – it’s important to let users know when they’re looking at a neural network creation and when it’s a real photo. The article emphasises that the labelling technology has so far only been successful for static images. Similar tools for audio and video content are more complex and are still under development.
Smaug-72B heads the open-source LLM ranking from Hugging Face
Last but not least, news about LLM dragons. Recently, the startup Abacus AI released an open-source large language model called “Smaug-72B” (the name of the dragon in Tolkien’s The Hobbit), as VentureBeat informs. It wouldn’t have attracted so much attention if the model hadn’t been at the top of the Hugging Face Open LLM leaderboard, which ranks open-source LLMs according to how well they do at various tasks: math, logic, commonsense reasoning, etc. Smaug-72B outperformed in the competition and became the first open-source LLM to have an average rating score above 80. The model has proven to be especially good at commonsense reasoning.