


В этом выпуске #ВобъективеИИ вас ждет информация об очередных успехах Китая в мировой ИИ-гонке, влиянии GPT-4 на формирование биологических угроз, новом рекорде open-source LLM и инициативах по маркировке в соцсетях картинок, сгенерированных ИИ. Ну и полезным будет познакомиться с рекомендациями от Apple по эффективному использованию ресурсов при разработке ИИ-моделей.
AI-focused digest – новости ИИ-сферы
Выпуск №35, 25 января – 8 февраля 2024
Китайские власти одобрили еще 14 отечественных LLM и ИИ-приложений
Власти Китая в последнюю неделю января одобрили для общего использования еще одну партию отечественных ИИ-моделей. В нее попали 14 LLM и базирующихся на генеративной технологии корпоративных ИИ-приложений, в числе которых целый ряд моделей с отраслевой спецификой, сообщает South China Morning Post. Среди последних, в частности, представлены модели, ориентированные на поддержку производителей потребительских товаров, решение проблем в области информационной безопасности и выполнение различных задач в сфере рекламы, образования, медиа и электронной торговли. Практика одобрения генеративных ИИ-моделей и решений на их основе для общего использования действует в Поднебесной с августа 2023 года. Reuters пишет, что с учетом этой последней партии за полгода государственную проверку в Китае прошли более 40 ИИ-моделей.
OpenAI оценила риски использования GPT-4 для создания биологических угроз
Эксперты из OpenAI по результатам весьма масштабного эксперимента пришли к выводу, что GPT-4 пока ненамного повышает возможности злоумышленников в создании биологических угроз. Однако этому риску стоит уделить повышенное внимание и заранее проработать меры для его предупреждения, так как технология развивается стремительно. Чтобы оценить, насколько GPT-4 может быть опасен в недобросовестных руках, компания привлекла к эксперименту 50 экспертов в области биологии и 50 студентов-биологов. Участников распределили на две группы. Членам одной из них предложили выполнить тот или иной набор задач для создания биологической угрозы, используя только интернет-ресурсы, – без доступа к ИИ. Испытуемые из второй группы для этого могли свободно пользоваться GPT-4. Выяснилось, что привлечение LLM лишь в незначительной мере повлияло на результативность участников — показатели группы, использовавшей GPT-4, были немногим лучше результатов первой. Подробно об эксперименте и выводах из него можно почитать здесь.
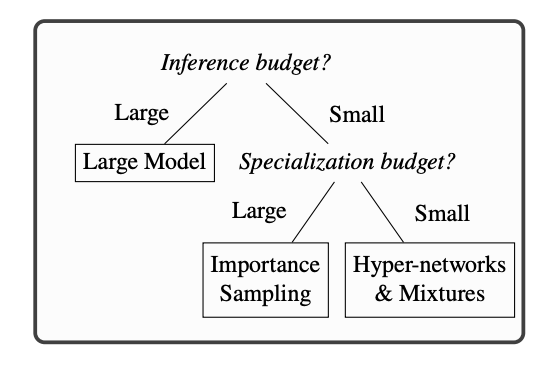
Apple представила рекомендации для эффективной разработки ИИ-моделей при ограниченных ресурсах
Исследователи из Apple на днях опубликовали статью, в которой представили свое видение, как наиболее эффективно распоряжаться бюджетом, точнее вычислительными ресурсами, для обучения ИИ-моделей. Ученые сначала выделили четыре главных параметра, которые влияют на работу и стоимость моделей. Это бюджет на предобучение (обучение до того, как станет известна целевая задача), бюджет на специализацию (обучение ИИ под определенную задачу), бюджет на работу модели после обучения и размер набора данных для обучения под конкретную задачу. Далее они изучили и проанализировали, учитывая вышеобозначенные переменные, различные подходы к созданию моделей: гиперсети, дистилляцию, смесь моделей (mixture of experts) и выборку по значимости. В итоге экспертам удалось по-эппловски минималистично сформировать рекомендации по выбору наиболее подходящей методики: если бюджет на специализацию большой (много вычислительных ресурсов), то лучше предварительное обучение с помощью выборки по значимости, а при меньшем бюджете стоит инвестировать в гиперсети и mixtures of experts. Все выводы у них уместились в эту инфографику (взята из исследования):
Пользователи соцсетей смогут отличать сгенерированные ИИ изображения от настоящих фото
Meta Platforms (признана экстремистской и запрещена в России) собирается в ближайшее время начать маркировать в своих социальных сетях изображения, созданные сервисами ИИ других компаний, включая OpenAI, Google, Microsoft, Adobe, Midjourney и Shutterstock. Картинки, сгенерированные своим ИИ, компания уже маркирует. Об этом пишет Reuters. Необходимость назрела давно — важно дать понять пользователям, когда перед ними творение нейросетей, а когда настоящая фотография. В материале подчеркивается, что технология маркировки пока успешно работает только для статичных изображений. Аналогичные же инструменты для аудио- и видеоконтента более сложны и пока находятся на стадии разработки.
Новая модель Smaug-72B возглавила рейтинг открытых LLM от Hugging Face
Ну и напоследок новость об LLM-драконах. Стартап Abacus AI на днях выпустил новую большую языковую модель с открытым исходным кодом под именем Smaug-72B (так зовут дракона в «Хоббите» Толкина). Об этом сообщает VentureBeat. И это не привлекло бы столько внимания, если бы модель с ходу не оказалась в самом верху списка Hugging Face Open LLM leaderboard, ранжирующего LLM с открытым кодом в зависимости от того, насколько хорошо они справляются с различными задачами – математическими, логическими, на повседневное мышление и прочими. Smaug-72B обошла конкурентов и стала первой LLM с открытым кодом, чей средний балл в рейтинге превысил 80. Модель оказалась особенно хороша в повседневном мышлении.














