


Зачем чистить данные, какие методы чистки существуют и какие алгоритмы чистки используются подробно рассказывает NLP-разработчик MTS AI Игорь Буянов.
Что? Зачем? Как? Чистим данные и тестируем алгоритмы в MTS AI
В работе над проектами группы обработки естественного языка Игорь Буянов, NLP-разработчик MTS AI, занимается подготовкой и обработкой датасетов. Ввиду случайных и неслучайных ошибок возникают различные источники шума, которые препятствуют получению желаемого результата.
В статье для Habr Игорь разобрал значение и применение чистки данных, а также подробно рассмотрел варианты алгоритмов, применяемых для очистки этих шумов, и результаты их тестирования.
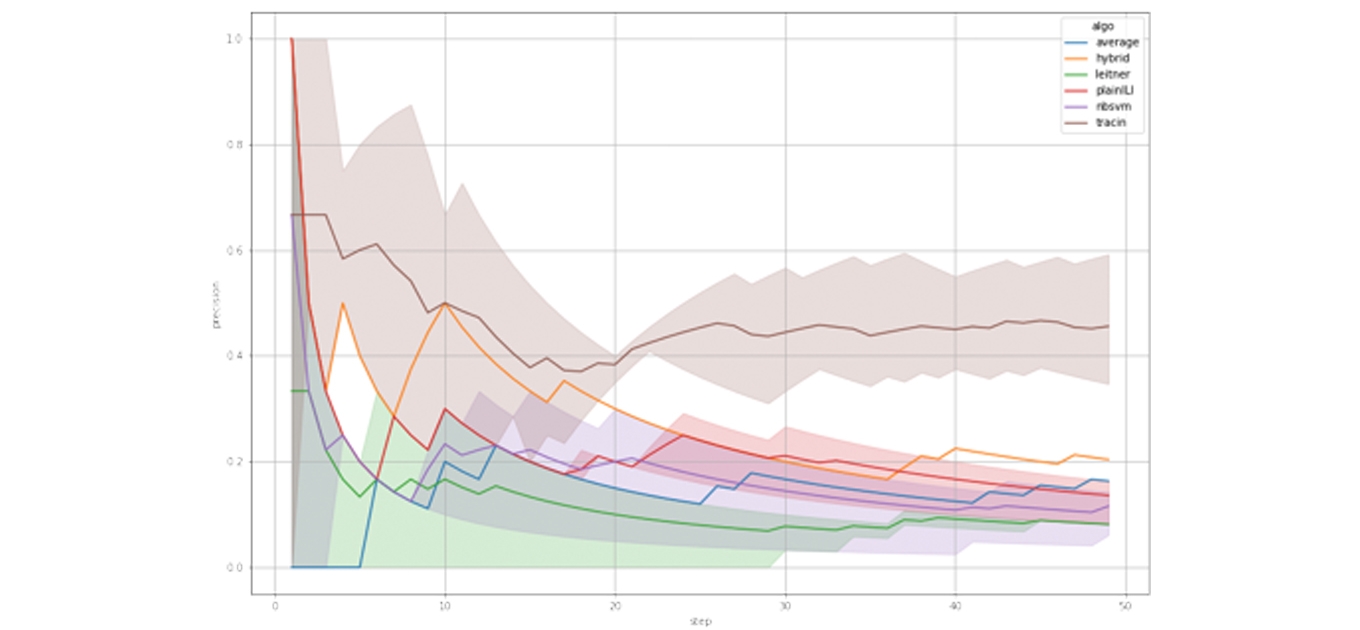
В подборку вошли шесть алгоритмов:
- averaged representation 1: основывается на гипотезе, что шумные и редкие примеры лежат далеко от усредненного по каждой метке отдельно центра в пространстве признаков;
- hybrid 2: модель может предсказывать истинный класс примера за счет генерализации;
- plainILI или Iterative Label Improvement 3 с гипотезой о модели предсказать истинный класс примера за счет генерализации;
- NBSVM 4 с более сложной иерархической структурой и использующий SVM для нахождения наиболее значимых примеров для классификации;
- Leitner system 5 с имитацией естественных процессов;
- TraceIn 6, главной задачей которого является определить влияние тренировочных примеров на предсказание примера тестовой выборки.
Какие концепции используют алгоритмы, из каких шагов состоят, при каких условиях проводилось их тестирование и какой из алгоритмов стал лидером по результатам тестирования, читайте в оригинальной статье на .










