

Руководство администратора Kodify
Аннотация
Документ «Руководство администратора» предназначен для сотрудников эксплуатирующей организации и отражает основную функциональность и порядок действий при выполнении операций, связанных с администрированием системы Kodify.
Перечень терминов
Таблица 1. Термины, используемые в руководстве Kodify.
| Термин | Описание |
|---|---|
| Авторизация | Процесс предоставления пользователю прав доступа к определенным ресурсам, функциям или данным системы после успешной аутентификации. |
| База данных (БД) | Организованная совокупность данных, которая хранится в электронном виде на компьютере или специальном сервере. |
| Искусственный интеллект | Область компьютерных наук, занимающаяся созданием вычислительных систем, способных выполнять задачи, требующие человеческого интеллекта, такие как восприятие, рассуждение, обучение и решение проблем. |
| Инференс модели | Процесс, в ходе которого система искусственного интеллекта использует ранее обученную модель для принятия решений на основе новых данных. |
| Кэш KV | В системе vLLM используется для эффективного хранения и быстрого доступа к данным, необходимым для работы моделей машинного обучения, особенно в трансформерных архитектурах. Он сохраняет результаты вычислений (ключи и значения внимания), которые могут быть повторно использованы для ускорения обработки последующих запросов. Это уменьшает необходимость в повторении трудоемких вычислений и оптимизирует использование памяти, что важно для поддержания высокой пропускной способности и эффективности системы. |
| Токен | Минимальная единица текста, например, слово или символ. Применяется в обработке естественного языка для анализа и генерации текста. |
| Docker | Платформа для автоматизации развёртывания вычислительных приложений в контейнерах. Обеспечивает изоляцию приложений и независимость от среды выполнения. |
Перечень сокращений
Таблица 2. Сокращения в руководстве Kodify.
| Сокращение | Описание |
|---|---|
| AI (Artificial Intelligence) | Интеллект, демонстрируемый машинами, в частности компьютерными системами. |
| API (Application Programming Interface) | Набор правил и инструментов для взаимодействия программного обеспечения. API предоставляет возможность различным приложениям обмениваться данными и функциональностью. |
| IDE (Integrated Development Environment) | Программа, в которой разработчики пишут, проверяют, тестируют и запускают код, а также ведут большие проекты. |
| JSON (JavaScript Object Notation) | Лёгкий формат обмена данными. Формат легко читается человеком и парсируется компьютером. |
| UI (User Interface) | Пользовательский интерфейс |
| vLLM (Virtual Large Language Model) | Сервис для инференса LLM модели и ее хранения |
Введение
Настоящий документ представляет собой руководство администратора (далее руководство) системы Kodify.
Руководство описывает:
- общее определение системы;
- функции системы;
- описание взаимодействия сервисов системы;
- требования к уровню подготовки администратора системы;
- программные и аппаратные требования для работы с системой;
- установку и настройку системы.
Назначение системы и ее состав
Назначение системы
Kodify от МWS AI представляет собой AI-ассистента разработчика. Этот инструмент использует искусственный интеллект для автоматизации рутинных процессов и помощи разработчикам в выполнении различных задач при написании программного кода.
Система предназначена для облегчения процесса разработки, предоставляя инструменты для генерации кода, улучшения его качества и автоматизации рутинных задач. Kodify поддерживает различные языки программирования (например, Python, C#, Java, Go, JavaScript) и интеграции с популярными инструментами разработки.
Сервисы Kodify
Система Kodify состоит из следующих сервисов:
Таблица 3. Сервисы Kodify.
| Сервис | Описание |
|---|---|
| Плагин для установки в IDE | Плагин представляет собой пользовательский интерфейс для взаимодействия с Kodify. Поддерживается плагин для JetBrains и Visual Studio Code. |
| API Сервер | Сервер для взаимодействия с LLM моделью через REST API. |
| Model Server (vLLM) | Сервис для инференса LLM модели и ее хранения. |
| PostgreSQL | БД с данными об учетной записи пользователей, используемая для пользовательской авторизации и журналирования. При иных типах авторизации - не используется. |
Описание взаимодействия сервисов
На следующей схеме показано взаимодействие сервисов Kodify.
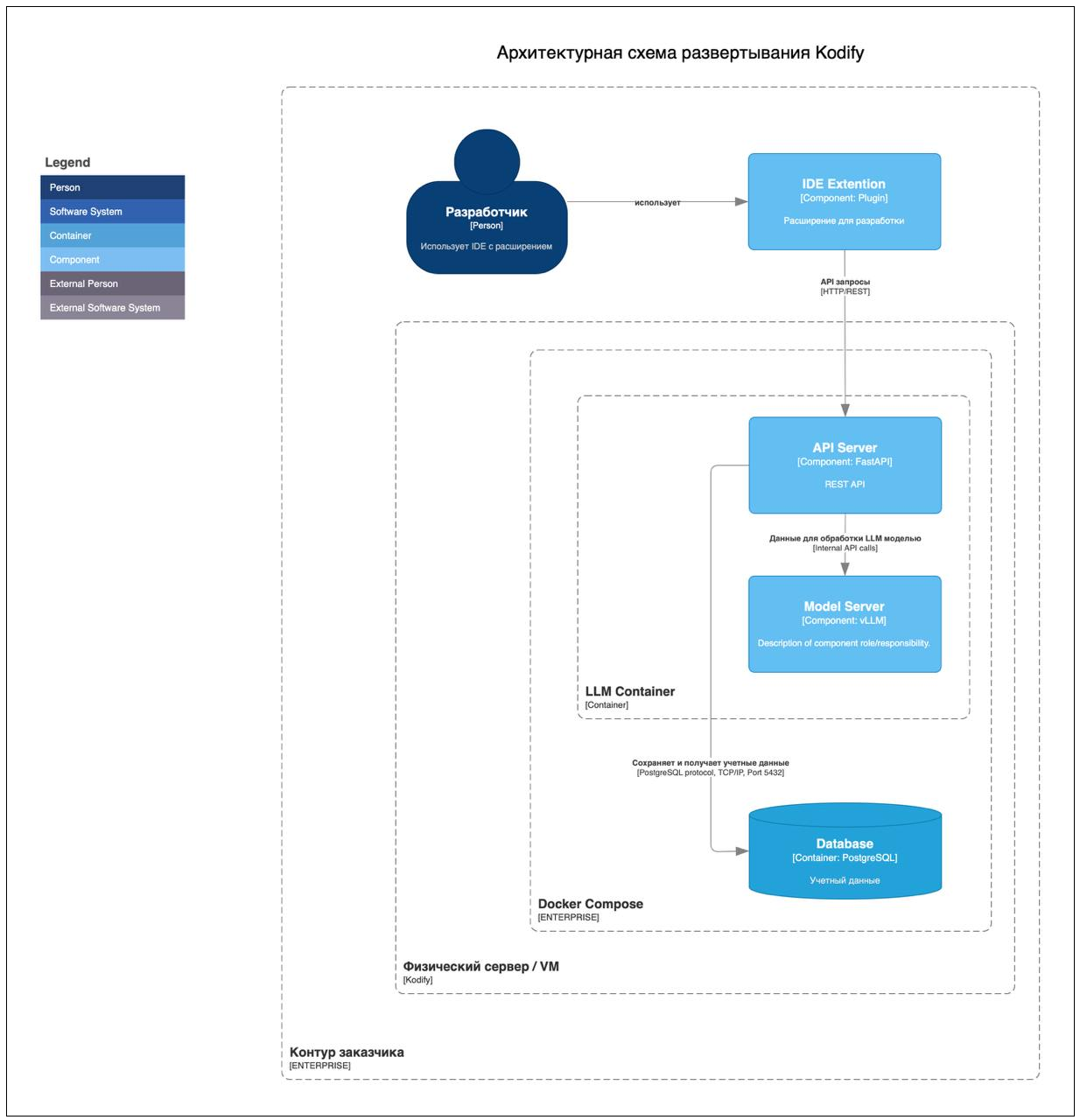
Kodify представляет собой LLM и плагин, встраиваемый в IDE от JetBrains (например, PyCharm) и Visual Studio Code. Взаимодействие пользователя с LLM Kodify осуществляется через пользовательский интерфейс (UI) в виде плагина. Плагин содержит набор функций для упрощения и ускорения процесса написания кода за счёт обращения к LLM.
Kodify предоставляет REST API (API сервер), к которому обращается плагин, установленный в IDE. Далее запрос отправляется на обработку LLM-моделью в Model Server.
Краткое описание функций
Система Kodify поставляется со следующими функциями:
- Автопродление кода с помощью LLM, которая на основе уже написанного пользователем кода генерирует завершение строки.
- Документирование кода
- Поиск ошибок в коде и исправление найденных ошибок.
- Формирование Unit-тестов для кода пользователя.
- Объяснение кода.
Требования к уровню подготовки
Требования к подготовке администратора:
- высокий уровень квалификации;
- наличие практического опыта выполнения работ по установке, настройке и администрированию программных и технических средств.
Перечень эксплуатационной документации
Ниже представлен список пользовательской документации системы:
- Руководство администратора системы Kodify
- Руководство пользователя системы Kodify.
Условия применения системы
Требования к программному обеспечению
Для работы системы необходимо, чтобы выполнялись следующие требования к программному обеспечению:
Таблица 4. Требования к программному обеспечению.
| Ресурс | Требования |
|---|---|
| Операционная система | Linux: Ubuntu или Astra Linux |
| Рекомендованная ОС | Ubuntu 24.04 LTS (Noble Numbat) › Ubuntu 22.04.4 LTS (Jammy Jellyfish) › Ubuntu 20.04.6 LTS (Focal Fossa) Oracle Linux Поддерживается работа на Astra Linux |
| Docker | Docker version 24.0.4+ Kubernetes 1.24+ |
| Nvidia-Docker | NVIDIA Container Toolkit NVIDIA Driver версия 525.105.17+ CUDA версия 12.0+ |
| Интернет | Наличие доступа к Интернет для скачивания образов при установке сервиса. Для работы сервиса доступ к Интернет не требуется. |
Требования к аппаратному обеспечению
Для работы системы необходимо, чтобы выполнялись следующие требования к аппаратным ресурсам:
Таблица 5. Требования к аппаратному обеспечению.
| Ресурс | Требования |
|---|---|
| CPU | от 8-16 ядер, процессор с наибольшей one thread скоростью |
| RAM | от 28 GB |
| GPU | минимум 20 Gb, рекомендовано - 40-80 GB. A100 40/80Gb / H100 80Gb |
| SSD | 100 GB - 1 TB |
Установка системы
Для установки системы в собственной инфраструктуре, выполните следующие шаги:
Скачайте файлы и авторизуйтесь в Artifactory
Скачайте файлы docker-compose или compose, ENV-файл и config.yml - при наличии. Вам будут переданы логин и пароль от учетной записи Artifactory.
Перейдите по ссылке https://artifactory.mts.ai/ui/login/ и пройдите аутентификацию, используя полученные учётные данные. Ссылку на папку с вашим образом вам предоставят отдельно.
Поместите скачанные файлы в желаемую директорию.
Проверьте и сконфигурируйте ENV-файл, docker-compose и config.yml файлы
Ознакомьтесь с содержимым ENV-файла, который передан вместе с docker-compose и config.yml файлами. ENV-файл содержит значения переменных окружения. При необходимости, сконфигурируйте переменные.
Подробнее о переменных окружения смотрите в разделе - Проверка и конфигурация ENV-файла.
Также проверьте заполнение docker-compose файла. Все переменные должны быть заполнены как на скриншоте ниже. Редактировать можно только переменную ports, если вы хотите указать иной адрес для приложения.
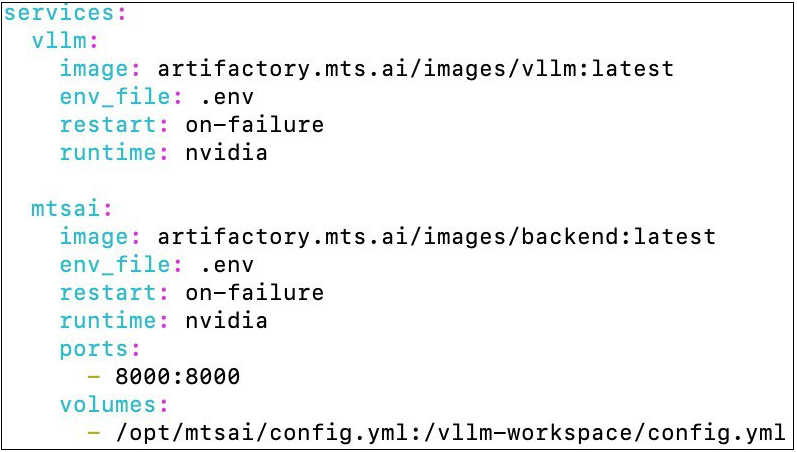
Файл config.yml необходимо добавить в директорию /opt/mtsai, которую перед этим нужно создать. Вы также можете указать путь до config.yml в текущей директории:
volumes:
./config.yml:/vllm-workspace/config.yml
При использовании пользовательской авторизации (ENV-переменная MTSAI_AUTH=true и AUTH_TYPE=DB), вы можете развернуть базу данных PostgreSQL (работает на версии 16.4, но нет жестких требований к версии) одновременно с сервисом, используя Docker Compose. Для этого добавьте в docker-compose.yml сервис базы данных:
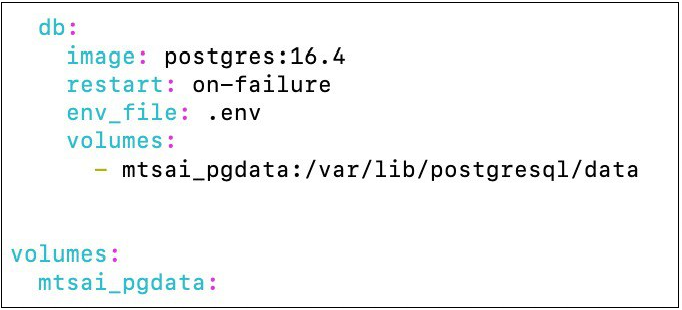
Volume (mtsai_pgdata) обеспечивает сохранность данных базы между перезапусками контейнера. Данные будут храниться в директории
/var/lib/postgresql/dataвнутри контейнера и будут доступны после остановки и удаления контейнера.
В ENV-файл для сервиса базы данных добавьте переменную окружения:
POSTGRES_PASSWORD=<CHANGE THIS>
При развертывании системы на нескольких видеокартах, добавьте в docker-compose.yml дополнительный параметр:
shm_size: 10g
Где shm_size - размер RAM памяти, которая хранит в себе промежуточные данные работы LLM, используемые в параллельных процессах на разных GPU.
Необходимый размер shm_size может варьироваться в зависимости от используемой LLM, количества GPU и других факторов. Рекомендуется установить значение shm_size равным 10g.
Настройка модели для tabby запросов
Для отправки запросов к модели в формате tabby, укажите в config.yml ключ tabby, у которого вы можете указать вложенный ключ model_name. В model_name укажите имя модели.
tabby:
model_name: tabby_model_nameПо умолчанию, запросы в формате tabby обрабатываются первой моделью в списке upstreams в файле config.yml. В случае, когда API-сервер обслуживает несколько моделей и требуется указать какая именно модель будет обрабатывать запросы tabby, вы можете указать имя модели в tabby.model_name.
upstreams:
http://upstream1:8000:
http://upstream2:8000:
tabby:
model_name: tabby_model_nameЗалогиньтесь в Artifactory
Залогиньтесь в Artifactory с использованием вашей учетной записи через команду:
docker login artifactory.mts.aiМигрируйте БД (опционально)
Актуально в том случае, если планируется использовать журналирование (значение переменной LOGS в ENV-файле - "True"). Если журналирование отключено, то данный этап можно пропустить и перейти к следующему шагу.
Для выполнения миграции БД, установите переменную окружения в ENV-файле RUN_MIGRATIONS в значение "1".
Если приложение эксплуатируется в среде Kubernetes, создайте init-контейнер с тем же образом, что и в основном контейнере сервиса. В нём используйте команду:
alembic -c /vllm-workspace/middleware/gpt_logger/alembic.ini upgrade headДля подключения к БД укажите переменные окружения. Подробнее о переменных смотрите в разделе - Переменные базы данных.
Запустите контейнер
Запустите контейнер с помощью команды:
docker compose up -d Убедитесь, что у вас установлен Docker Compose.
Проверьте работу системы
Проверьте, что система работает корректно одним из следующих способов:
-
С помощью API-запроса
GET/health. -
Откройте логи контейнера с помощью команды:
docker logs CONTAINER_ID
При успешной установке приложения в логах отобразится следующее:
INFO: Application startup complete/
INFO: Unicorn running on http://. . . . .Проверка и конфигурация ENV-файла
Вместе с docker-compose файлом вам будет передан ENV-файл, который содержит значения переменных окружения. В файле вы можете задать или изменить переменные, указанные ниже.
Переменные потребления видеопамяти
Переменные потребления видеопамяти (VRAM) используются для контроля за распределением и использованием графической памяти на GPU. Эти переменные устанавливают максимальный объём видеопамяти, доступный для использования.
Таблица 6. Переменные потребления видеопамяти.
| Переменная | Определение |
|---|---|
| GPUUTIL | Переменная определяет значение, передаваемое в аргумент --gpu_memory_utilization, и долю видеопамяти GPU, которая будет зарезервирована для использования модели, включая память для весов модели, активации и KV кэша (ключ-значение). Значение этой переменной может варьироваться от 0 до 1. Значение 0.9 означает, что 90% видеопамяти GPU будет зарезервировано. Это позволяет увеличить размер кэша KV, что может улучшить пропускную способность модели. В случае, если на видеокарте, выделенной под сервис, запущено еще какое-то ПО, то параметр GPUUTIL можно рассчитать по формуле: GPUUTIL = GPU_for_Kodify/GPU_total, где GPU_total - общее количество видеопамяти, GPU_for_Kodify - количество видеопамяти, которое вы планируете выделить под Kodify. |
| DTYPE | Определяет то, в каком типе данных используются веса модели (auto, half, float16, bfloat16, float, float32). По умолчанию установлен на тип данных, совместимый с видеокартой A100 80 GB. В этом случае нет необходимости добавлять параметр в ENV-файл. Если вы собираетесь использовать иную видеокарту, то обратитесь за консультацией к специалисту со стороны MWS AI, вам подскажут какое значение переменной необходимо установить. |
| EAGER | Эта переменная активирует флаг --enforce_eager для vLLM (по умолчанию - eager mode отключен, но при указании флага - включается). Для выставления этого аргумента при запуске контейнера, передайте в контейнер значение переменной EAGER=1, а для отключения - оставьте пустым EAGER= |
Переменные для запуска сервиса на нескольких видеокартах
В данном подразделе перечислены переменные окружения для запуска сервиса, необходимые для корректной работы сервиса при использовании нескольких видеокарт.
Таблица 7. Переменные окружения для запуска сервиса на нескольких видеокартах.
| Переменная | Определение |
|---|---|
| PYTORCH_CUDA_ALLOC_CONF | В случае если сервер перезапускается при инференсе системы из-за нехватки памяти, следует использовать данную переменную со значением PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True. Это уменьшает количество резервируемой памяти pytorch, что решает проблему падения. В ином случае, использовать данную переменную не следует. |
| NVIDIA_VISIBLE_DEVICES | Использовать все GPU устройства. Для указания конкретной видеокарты, укажите ее индекс в этой переменной. |
| VLLM_WORKER_MULTIPROC_METHOD | Использовать выделенный многопроцессорный контекст для рабочих процессов. |
Дополнительные аргументы для запуска сервиса на нескольких видеокартах
В данном подразделе перечислены дополнительные аргументы tensor-parallel-size и pipeline-parallel-size, которые передаются в строку запуска приложения через переменную окружения ADDITIONAL_ARGS.
Таблица 8. Дополнительные аргументы для запуска сервиса на нескольких видеокартах.
| Переменная | Определение |
|---|---|
| tensor-parallel-size | Перед использованием проконсультируйтесь с сотрудником MWS AI, так как в зависимости от количества видеокарт и используемой модели Kodify, может потребоваться или переменная --tensor-parallel-size, или --pipeline-parallel-size.Пример заполнения: ADDITIONAL_ARGS=--tensor-parallel-size = <количество карт> |
| pipeline-parallel-size | Перед использованием проконсультируйтесь с сотрудником MWS AI, так как в зависимости от количества видеокарт и используемой модели Kodify, может потребоваться или аргумент --tensor-parallel-size, или --pipeline-parallel-size.Пример заполнения: ADDITIONAL_ARGS =--pipeline-parallel-size = <количество карт> |
Переменные авторизации
Переменные авторизации используются для хранения и управления данными, необходимыми для аутентификации и авторизации пользователей в системе.
Таблица 9. Переменные авторизации
| Переменная | Определение |
|---|---|
| MTSAI_AUTH | Этот параметр определяет метод авторизации. При установке значения true, активируется пользовательская авторизация, которая требует специфических данных аутентификации. Значение false активирует однотокеновую или dummy авторизацию. Выбор между однотокеновой и dummy авторизацией зависит от значения переменной VLLM_API_KEY. |
| AUTH_TYPE | Признак использования пользовательской авторизации. Если вы используете пользовательскую авторизацию, следует указать значение "DB". Дефолтное значение "NO", можно не указывать если используйте иной тип авторизации. |
| VLLM_API_KEY | Токен авторизации. Строка, указывающая токен для авторизации, одинаковый для всех пользователей системы. Необходимо заполнить только в том случае, если AUTH_TYPE: "NO". Любое значение, которое вы укажете, станет токеном и будет активирована однотокеновая авторизация. |
Однотокеновая авторизация (one-token auth) — это авторизация, при которой существует только один токен, способный пройти авторизацию (его значение необходимо задать в рамках конфигурации ENV).
Пользовательская авторизация - это авторизация, при которой каждому пользователю создается уникальный токен. Информация о пользователях хранится в БД.
Переменные базы данных
Переменные базы данных используются для хранения конфигурационных данных, необходимых для подключения и работы с базой данных при включённой пользовательской авторизации (MTSAI_AUTH = true и AUTH_TYPE = DB). Не используются при ином типе авторизации и отсутствуют по умолчанию в ENV-файле. Добавьте их в файл вручную только в том случае, если вам необходима пользовательская авторизация.
Таблица 10. Переменные базы данных.
| Переменная | Определение |
|---|---|
| USERS_TABLE | Идентификатор таблицы в базе данных PostgreSQL. Требует указания полного имени таблицы. Этот параметр необходим, когда используется пользовательская авторизация для хранения имени таблицы с данными о пользователях. |
| DB_URL | URL для подключения к БД при аутентификации через БД. Заполняется следующим образом:DB_URL=postgresql://${DB_USER}:${DB_PASSWORD}@${DB_HOST}:${DB_PORT}/${DB_NAME}Содержит информацию о БД с пользователями и данные для подключения к этой БД. Не используется при ином типе авторизации, кроме пользовательской. |
| RUN_MIGRATIONS | Для выполнения миграций БД, установите значение этой переменной в значение "1". |
При первом запуске система автоматически создаст необходимую базу данных и таблицу пользователей. Дополнительных действий по инициализации базы данных не требуется.
Переменные настройки генерации модели
Переменные настройки генерации модели устанавливают ограничения при обработке запросов POST/v1/chat/completions.
Таблица 11. Переменные настройки генерации модели.
| Переменная | Определение |
|---|---|
| MAX_N | Устанавливает ограничение для опционального параметра "n", использующегося в запросе POST/v1/chat/completions. Параметр отвечает за то, сколько ответов модель сгенерирует по запросу пользователя. Необходимо установить максимально допустимое значение для параметра "n", чтобы избежать ситуации, когда пользователь задал слишком большой "n" и на один запрос модель генерирует сотни или тысячи ответов. Значение MAX_N по умолчанию: 10. |
| COMPLETIONS_PREPROCESSING_CONFIG | Путь к файлу с настройками препроцессинга запросов. Используется для настройки работы функционала автодополнение в плагине. |
Переменные журналирования
Переменные журналирования используются для настройки журналирования API-запросов и определения таблицы БД, куда будет сохранён журнал обработки пользовательских запросов. Все переменные из данного раздела обязательны к заполнению, кроме переменной LOGS.
Таблица 12. Переменные журналирования.
| Переменная | Определение |
|---|---|
| LOGS | Журналирование отключено по умолчанию. Для того чтобы его активировать нужно указать значение переменной True. Если не установить данное значение и не указывать переменную в ENV-файле, то журналирование будет отключено. |
| LOGS_DB_HOST | Адрес сервера PostgreSQL. |
| LOGS_DB_PORT | Порт PostgreSQL, куда будут сохраняться журнал запросов. |
| LOGS_DB_NAME | Имя базы данных, в которую будут сохраняться журнал запросов. |
| LOGS_DB_USERNAME | Имя пользователя для подключения к базе данных. |
| LOGS_DB_PASSWORD | Пароль пользователя для подключения к базе данных. |
Переменные движка ядра vLLM
Таблица 13. Переменные движка ядра.
| Переменная | Определение |
|---|---|
| VLLM_USE_V1 | Включает альфа версию нового ядра vLLM для версии 0.7.2, если VLLM_USE_V1 = 1. Это позволяет увеличить скорость генерации ответа до 1.7х и обеспечивает постоянно включенный prefix caching. Значение переменной по умолчанию: 0. |
| WAIT_VLLM | Включает режим ожидания доступности первого в списке сервиса vLLM. По умолчанию выполняется 5 попыток подключения с таймаутом между попытками в 10 секунд. Используйте эту переменную для случаев, когда приложение запускается в среде без оркестрирования сервисов и нельзя гарантировать старт сервисов vLLM раньше сервиса backend. |
| WAIT_VLLM_ATTEMPTS | Изменяет количество попыток подключения сервиса vLLM. По умолчанию задано 5 попыток подключения. |
| WAIT_VLLM_TIMEOUT | Задает таймаут ожидания между попытками подключения сервиса vLLM. По умолчанию таймаут задан в 10 секунд. |
Настройка функции автодополнения
Для работы функции автодополнения кода в плагине, добавьте в ENV-файл переменную COMPLETIONS_PREPROCESSING_CONFIG со следующей настройкой:
COMPLETIONS_PREPROCESSING_CONFIG=preprocess_configs/qwen.json
Примеры заполнения ENV-файла
Однотокеновая авторизация
GPUUTIL: 0.9
MTSAI_AUTH: false
VLLM_API_KEY:<токен авторизации>
USERS_TABLE: <переменная отсутствует>
AUTH_TYPE: <переменная отсутствует>
DB_URL: <переменная отсутствует>
MAX_N: 10
Пользовательская авторизация
GPUUTIL: 0.9
MTSAI_AUTH: true
VLLM_API_KEY: <переменная отсутствует>
USERS_TABLE: <идентификатор таблицы>
AUTH_TYPE: DB
DB_URL:postgresql://${DB_USER}:${DB_PASSWORD}@${DB_HOST}:${DB_PORT}/${DB_NAME}
MAX_N: 10
Отключение журналирования
LOGS – переменная отсутствует в ENV-файле
LOGS_DB_HOST: <HOST>
LOGS_DB_POST: <PORT>
LOGS_DB_NAME: <DB_NAME>
LOGS_DB_USERNAME: <USERNAME>
LOGS_DB_PASSWORD: <PASSWORD>
Переменные журналирования, кроме LOGS, обязательны к заполнению, даже если вы хотите, чтобы журналирование было отключено. Они необходимы для корректного запуска приложения.
Активное журналирование
LOGS: True
LOGS_DB_HOST: <HOST>
LOGS_DB_POST: <PORT>
LOGS_DB_NAME: <DB_NAME>
LOGS_DB_USERNAME: <USERNAME>
LOGS_DB_PASSWORD: <PASSWORD>
При необходимости, скорректируйте значения переменных в ENV-файле.
После внесения изменений, поместите ENV-файл в ту же директорию, где находится docker-compose.yml.
