

Руководство администратора Cotype
Аннотация
Документ «Руководство администратора» предназначен для сотрудников эксплуатирующей организации и отражает основную функциональность и порядок действий при выполнении операций, связанных с администрированием системы Cotype.
Перечень терминов
Таблица 1. Термины, используемые в руководстве Cotype.
| Термин | Описание |
|---|---|
| Авторизация | Процесс предоставления пользователю прав доступа к определенным ресурсам, функциям или данным системы после успешной аутентификации. |
| Аутентификация | Процесс подтверждения права на доступ с помощью ввода пароля, пин-кода, использования биометрических данных и других способов. |
| База данных (БД) | Организованная совокупность данных, которая хранится в электронном виде на компьютере или специальном сервере. |
| Искусственный интеллект | Область компьютерных наук, занимающаяся созданием вычислительных систем, способных выполнять задачи, требующие человеческого интеллекта, такие как восприятие, рассуждение, обучение и решение проблем. |
| Инференс модели | Процесс, в ходе которого система искусственного интеллекта использует ранее обученную модель для принятия решений на основе новых данных. |
| Кэш KV | В системе vLLM используется для эффективного хранения и быстрого доступа к данным, необходимым для работы моделей машинного обучения, особенно в трансформерных архитектурах. Он сохраняет результаты вычислений (ключи и значения внимания), которые могут быть повторно использованы для ускорения обработки последующих запросов. Это уменьшает необходимость в повторении трудоемких вычислений и оптимизирует использование памяти, что важно для поддержания высокой пропускной способности и эффективности системы. |
| Токен | Минимальная единица текста, например, слово или символ. Применяется в обработке естественного языка для анализа и генерации текста. |
| Docker | Платформа для автоматизации развёртывания вычислительных приложений в контейнерах. Обеспечивает изоляцию приложений и независимость от среды выполнения. |
Перечень сокращений
Таблица 2. Сокращения в руководстве Cotype.
| Сокращение | Описание |
|---|---|
| AI (Artificial Intelligence) | Интеллект, демонстрируемый машинами, в частности компьютерными системами. |
| API (Application Programming Interface) | Набор правил и инструментов для взаимодействия программного обеспечения. API предоставляет возможность различным приложениям обмениваться данными и функциональностью. |
| JSON (JavaScript Object Notation) | Лёгкий формат обмена данными. Формат легко читается человеком и парсируется компьютером. |
| LLM (Large Language Model) | Языковая модель, состоящая из нейронной сети со множеством параметров. |
| vLLM (Virtual Large Language Model) | Сервис для инференса LLM модели и ее хранения |
Введение
Настоящий документ представляет собой руководство администратора (далее руководство) системы Cotype. Руководство описывает:
- общее определение системы;
- функции системы;
- описание взаимодействия сервисов системы;
- требования к уровню подготовки администратора системы;
- программные и аппаратные требования для работы с системой;
- установку и настройку системы.
Назначение системы и ее состав
Назначение системы
Cotype — это большая языковая модель для генерации и редактирования текстов, суммирования и анализа информации. Cotype включает в себя также веб-приложение для ее запуска и использования.
В каждую модель, предоставляемую нашим клиентам и партнерам, встроен уникальный водяной знак. Это необходимо для установления факта утечки модели от клиента или партнера. Просим вас ответственно относиться к обеспечению безопасности хранения модели.
Сервисы Cotype и их функции
Система Cotype состоит из следующих сервисов:
Таблица 3. Сервисы Cotype.
| Сервис | Описание |
|---|---|
| Чат-интерфейс | Веб-приложение, предназначенное для взаимодействия с LLM через веб-интерфейс. |
| vLLM | Сервис для инференса LLM модели и ее хранения. |
| Backend-App | Компонент, в котором реализован сервис аутентификации и авторизации, журналирование и обработка API-запросов. |
| PostgreSQL | БД с данными об учетной записи пользователей, используемые для пользовательской авторизации и журналирования. При иных типах авторизации - не используется. |
В следующих подразделах подробно описан состав каждого сервиса и его функции.
Чат-интерфейс
Веб-интерфейс Cotype позволяет пользователю выполнять следующие задачи:
- Тестировать и валидировать ответы модели для проверки ее корректности и получения от нее ожидаемых результатов.
- Настраивать промпты и параметры языковой модели для тонкой настройки ее работы и адаптации к конкретным задачам.
- Интерактивно взаимодействовать с моделью в режиме чата для получения ответов на вопросы и отображения результатов работы модели в реальном времени.
vLLM
Сервис для инференса LLM модели и ее хранения.
Функции сервиса:
- Хранение и управление LLM моделью;
- Обработка запросов к модели;
- Генерация ответов.
BACKEND-APP
Компонент, который непосредственно взаимодействует с vLLM. В состав компонента входит: шлюз API, cервис аутентификации и авторизации и журналирование.
Шлюз API
Шлюз API — это компонент, который обеспечивает доступ к языковой модели (LLM) для внешних сервисов, разработанный с использованием FastAPI. Он играет роль посредника между внешними системами и LLM, обрабатывая запросы, передавая их в языковую модель и возвращая ответы обратно внешним сервисам.
Функции шлюза API:
- Обработка входящих запросов от внешних сервисов с возможностью определения типа запроса, его валидации и авторизации.
- Взаимодействие с LLM для получения ответов на запросы, что включает в себя передачу параметров и настройку модели для обеспечения точности и релевантности ответов.
- Возврат ответов от LLM внешним сервисам.
Сервис аутентификации и авторизации
Сервис отвечает за проверку токенов пользователей. Каждый входящий в API запрос проходит через этот компонент для проверки подлинности. Сервис поддерживает следующие виды авторизации:
-
Пользовательская авторизация
Этот метод предполагает использование конкретных учетных данных пользователя, таких как токены или пароли, для предоставления доступа. Он обеспечивает высокий уровень безопасности, позволяя точно контролировать доступ к ресурсам.
-
Однотокеновая авторизация
В этом случае система использует единственный токен для авторизации всех пользователей. Такой подход применяется, когда необходим простой и быстрый контроль доступа, но он менее безопасен, по сравнению с пользовательской авторизацией.
Вид авторизации можно установить через переменные окружения. Подробности смотрите в разделе Проверка и конфигурация ENV-файла.
Функции сервиса:
- Хранение данных пользователей в PostgreSQL базе данных;
- Проверка подлинности запросов;
- Выдача токенов аутентификации.
Журналирование
Система формирует журнал с запросами пользователей к LLM модели и полученными ответами от нее, если включены соответствующие параметры в ENV-файле. Журнал хранится в БД, в PostgreSQL.
Подробнее о переменных смотрите в разделе Переменные журналирования.
PostgreSQL
БД с данными c УЗ пользователей, используемые для пользовательской авторизации и журналирования. При иных типах авторизации не используется.
Требования к уровню подготовки
Требования к подготовке администратора:
- высокий уровень квалификации;
- наличие практического опыта выполнения работ по установке, настройке и администрированию программных и технических средств.
Перечень эксплуатационной документации
Ниже представлен список пользовательской документации системы:
- Руководство администратора системы Cotype.
- Руководство пользователя системы Cotype.
Условия применения системы
Требования к программному обеспечению
Для работы системы необходимо, чтобы выполнялись следующие требования к программному обеспечению:
Таблица 4. Требования к программному обеспечению.
| Ресурс | Требования |
|---|---|
| Рекомендованная ОС | Ubuntu 24.04 LTS (Noble Numbat) › Ubuntu 22.04.4 LTS (Jammy Jellyfish) › Ubuntu 20.04.6 LTS (Focal Fossa) Rockylinux8 Поддерживается работа на Astra Linux |
| Docker | Docker version 24.0.4 + Kubernetes 1.24 + |
| Nvidia-Docker NVIDIA Container Toolkit |
NVIDIA Container Toolkit NVIDIA Driver версия 525.105.17+ CUDA версия 12.0+ |
| Интернет | Наличие доступа к Интернет для контейнеров и дополнительных загрузок ПО при установке сервиса. Для работы сервиса доступ к Интернет не требуется. |
Требования к аппаратному обеспечению
Для работы системы необходимо, чтобы выполнялись следующие требования к аппаратным ресурсам:
Таблица 5. Минимальные требования к аппаратному обеспечению.
| Ресурс | Требования |
|---|---|
| CPU | 16 ядер. Рекомендуется процессор с наибольшей one thread скоростью. |
| RAM | 48 GB |
| GPU | Минимум - 40 Gb, рекомендовано от 80 GB. A100 80Gb / H100 80Gb |
| Disk Space | 200 GB |
Установка системы
Для установки системы в собственной инфраструктуре, выполните следующие шаги:
Скачайте файлы
- Скачайте файлы docker-compose, ENV-файл и config.yml. Вам будут переданы логин и пароль от УЗ Artifactory.
- Перейдите по ссылке https://artifactory.mts.ai/ui/login/ и пройдите аутентификацию, используя полученные учётные данные. Ссылку на папку с вашим образом вам предоставят отдельно.
- Поместите скачанные файлы в желаемую директорию.
Проверьте и сконфигурируйте ENV-файл
Ознакомьтесь с содержимым ENV-файла, который передан вместе с docker-compose и config.yml файлами. ENV-файл содержит значения переменных окружения.
При необходимости, сконфигурируйте переменные. Подробнее о переменных рассказано в разделе Проверка и конфигурация ENV-файла.
Также проверьте заполнение docker-compose файла. Все переменные должны быть заполнены как на скриншоте ниже. Редактировать можно только переменную ports, если вы хотите указать иной адрес для приложения.
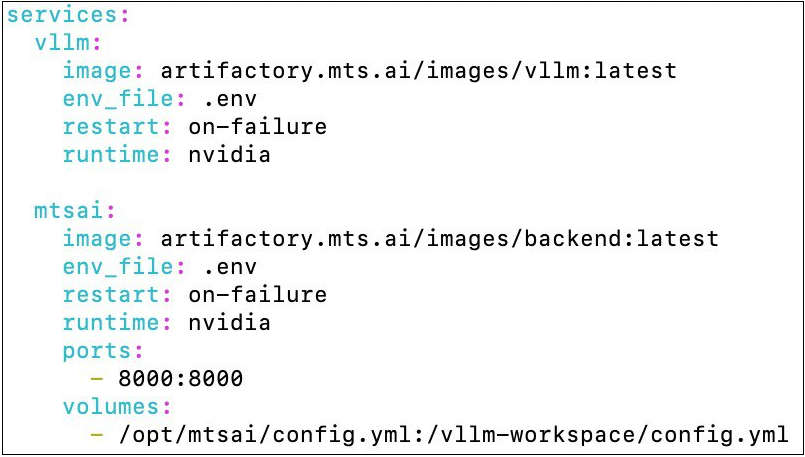
При использовании пользовательской авторизации (ENV-переменная MTSAI_AUTH=true и AUTH_TYPE=DB), вы можете развернуть базу данных PostgreSQL (работает на версии 16.4, но нет жестких требований к версии) одновременно с сервисом, используя Docker Compose. Для этого добавьте в docker-compose.yml сервис базы данных:

Volume (mtsai_pgdata)обеспечивает сохранность данных базы между перезапусками контейнера. Данные будут храниться в директории/var/lib/postgresql/dataвнутри контейнера и будут доступны после остановки и удаления контейнера.
В ENV-файл для сервиса базы данных добавьте переменную окружения:
POSTGRES_PASSWORD=<CHANGE THIS>При развертывании системы на нескольких видеокартах, добавьте в docker-compose.yml дополнительный параметр:
shm_size: 10gГде shm_size - размер RAM памяти, которая хранит в себе промежуточные данные работы LLM, используемые в параллельных процессах на разных GPU.
Необходимый размер shm_size может варьироваться в зависимости от используемой LLM, количества GPU и других факторов. Рекомендуется установить значение shm_size равным 10g.
Залогиньтесь в Artifactory
Залогиньтесь в Artifactory с использованием вашей учетной записи через команду:
docker login artifactory.mts.aiМигрируйте БД (опционально)
Актуально в том случае, если планируется использовать журналирование (значение переменной LOGS в ENV-файле - "True"). Если журналирование отключено, то данный этап можно пропустить и перейти к следующему шагу.
Для выполнения миграции БД, установите переменную окружения в ENV-файле RUN_MIGRATIONS в значение "1".
Если приложение эксплуатируется в среде Kubernetes, создайте init-контейнер с тем же образом, что и в основном контейнере сервиса. В нём используйте команду:
alembic -c /vllm-workspace/middleware/gpt_logger/alembic.ini upgrade head Для подключения к БД укажите переменные окружения. Подробнее о переменных смотрите в разделе Переменные базы данных.
Запустите контейнер
До запуска контейнера убедитесь, что у вас установлен Docker Compose.
Запустите контейнер с помощью команды:
docker compose up -d Проверьте работу системы
Проверьте, что система работает корректно одним из следующих способов:
- С помощью API-запроса
GET/health. Запрос подробно описан в разделе GET/health. -
Откройте логи контейнера с помощью команды:
docker logs CONTAINER_ID
При успешной установке приложения в логах отобразится следующее:
INFO: Application startup complete/
INFO: Unicorn running on http://. . . . .Проверка и конфигурация ENV-файла
Вместе с docker-compose файлом вам будет передан ENV-файл, который содержит значения переменных окружения. В файле вы можете задать или изменить переменные, указанные ниже.
Переменные потребления видеопамяти
Переменные потребления видеопамяти (VRAM) используются для контроля за распределением и использованием графической памяти на GPU. Эти переменные устанавливают максимальный объём видеопамяти, доступный для использования.
Таблица 6. Переменные потребления видеопамяти.
| Переменная | Определение |
|---|---|
| GPUUTIL | Переменная определяет значение, передаваемое в аргумент --gpu_memory_utilization, и долю видеопамяти GPU, которая будет зарезервирована для использования модели, включая память для весов модели, активации и KV-кэша (ключ-значение). Значение этой переменной может варьироваться от 0 до 1. Значение 0.9 означает, что 90% видеопамяти GPU будет зарезервировано. Это позволяет увеличить размер кэша KV, что может улучшить пропускную способность модели. В случае, если на видеокарте, выделенной под сервис, запущено еще какое-то ПО, то переменную GPUUTIL можно рассчитать по формуле:GPUUTIL = GPU_for_Cotype/GPU_total,где GPU_total - общее количество видеопамяти,GPU_for_Cotype - количество видеопамяти, которое вы планируете выделить под Cotype. GPU_for_Cotype также можно рассчитать, учитывая необходимый размер контекста, по формуле: GPU_for_Cotype = vectors_num * nums_precision * layers * kv_heads / attention_heads * (context_size + max_gen_tokens) / 1024^3 + model_size Где - vectors_num - количество векторов. Всегда постоянное значение 2, так как хранятся только два вектора: key и value; - nums_precision - размер в байтах одного числового значения. В основном, используются типы float16/bfloat16, которые имеют размер 2 байта. Следующие параметры хранятся в конфиге модели config.json: - layers - количество attention слоев модели; - kv_heads - количество голов key и value матриц; - attention_heads - количество голов attention. Следующие параметры настраиваются пользователем: - context_size - максимальный размер промпта в токенах; - max_gen_tokens - максимальный размер ответа в токенах; - model_size - размер модели в Гб. |
| DTYPE | Определяет то, в каком типе данных используются веса модели (auto, half, float16, bfloat16, float, float32). По умолчанию установлен на тип данных, совместимый с видеокартой A100 80 GB. В этом случае нет необходимости добавлять переменную в ENV-файл. Если вы собираетесь использовать иную видеокарту, то обратитесь за консультацией к специалисту со стороны MWS AI, вам подскажут какое значение переменной необходимо установить. |
| EAGER | Эта переменная активирует флаг --enforce_eager для vLLM (по умолчанию - eager mode отключен, но при указании флага - включается). Для выставления этого аргумента при запуске контейнера, передайте в контейнер значение переменной EAGER=1, а для отключения - оставьте пустым EAGER= |
Переменные для запуска сервиса на нескольких видеокартах
В данном подразделе перечислены переменные окружения для запуска сервиса, необходимые для корректной работы сервиса при использовании нескольких видеокарт.
Таблица 7.1. Переменные окружения для запуска сервиса на нескольких видеокартах.
| Переменная | Определение |
|---|---|
| PYTORCH_CUDA_ALLOC_CONF | В случае если сервер перезапускается при инференсе системы из-за нехватки памяти, следует использовать данную переменную с значением PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True. Это уменьшает количество резервируемой памяти pytorch, что решает проблему падения. В ином случае, использовать данную переменную не следует. |
| NVIDIA_VISIBLE_DEVICES | Использовать все GPU устройства. Для указания конкретной видеокарты, укажите ее индекс в этой переменной. |
| VLLM_WORKER_MULTIPROC_METHOD | Использовать выделенный многопроцессорный контекст для рабочих процессов. |
Дополнительные аргументы для запуска сервиса на нескольких видеокартах
В данном подразделе перечислены дополнительные аргументы tensor-parallel-size и pipeline-parallel-size, которые передаются в строку запуска приложения через переменную окружения ADDITIONAL_ARGS.
Таблица 7.2. Дополнительные аргументы для запуска сервиса на нескольких видеокартах.
| Переменная | Определение |
|---|---|
| tensor-parallel-size | Перед использованием проконсультируйтесь с сотрудником MWS AI, так как в зависимости от количества видеокарт и используемой модели Cotype, может потребоваться или переменная --tensor-parallel-size, или --pipeline-parallel-size. Пример заполнения: ADDITIONAL_ARGS=--tensor-parallel-size=<количество карт> |
| pipeline-parallel-size | Перед использованием проконсультируйтесь с сотрудником MWS AI, так как в зависимости от количества видеокарт и используемой модели Cotype, может потребоваться или аргумент --tensor-parallel-size, или --pipeline-parallel-size.Пример заполнения: ADDITIONAL_ARGS =--pipeline-parallel-size=<количество карт> |
Добавление функции Function Calling (Tool Use) через дополнительные аргументы
Function Calling (вызов функции) устанавливает общий протокол, который определяет, как LLM должны взаимодействовать с другими объектами.
Процедура состоит из следующих этапов:
- Приложение предоставляет набор функций и инструкций функций для LLM.
- LLM делает выбор или не делает выбора или вынуждена использовать одну или несколько функций в ответ на запросы пользователя.
- Если LLM решает использовать функции, то она определяет, как эти функции следует использовать, на основе инструкций по использованию.
- Выбранные функции используются приложением, и полученные результаты затем передаются LLM, если требуется дальнейшее взаимодействие.
Для активации Function Calling, добавьте перед запуском сервиса в ENV-файл для переменной ADDITIONAL_ARGS следующую строку:
--enable-auto-tool-choice --tool-call-parser <парсер>Флаг --enable-auto-tool-choice - сообщает vLLM, что вы даете разрешение модели генерировать ее собственные вызовы функций (тулов), когда она сочтет это нужным.
Флаг --tool-call-parser - выбирает парсер тула.
Для Cotype_pro_32k_1.1 - парсер llama3_json.
Для Cotype_pro_2 - парсер hermes.
Это позволит сервису работать с обработкой тулов.
Описание параметров для запроса POST/v1/chat/completions смотрите в разделе POST/v1/chat/completions.
Пример вызова модели с использованием тулов смотрите в разделе Пример выполнения запроса POST/v1/chat/completions с функцией tool-calling.
Переменные авторизации
Переменные авторизации используются для хранения и управления данными, необходимыми для аутентификации и авторизации пользователей в системе.
Таблица 8. Переменные авторизации.
| Переменная | Определение |
|---|---|
| MTSAI_AUTH | Этот параметр определяет метод авторизации. При установке значения true, активируется пользовательская авторизация, которая требует специфических данных аутентификации. Значение false активирует однотокеновую или dummy авторизацию. Выбор между однотокеновой и dummy авторизацией зависит от значения переменной VLLM_API_KEY. |
| AUTH_TYPE | Признак использования пользовательской авторизации. Если вы используете пользовательскую авторизацию, следует указать значение "DB". Дефолтное значение "NO", можно не указывать, если используйте иной тип авторизации. |
| VLLM_API_KEY | Токен авторизации. Строка, указывающая токен для авторизации, одинаковый для всех пользователей системы. Необходимо заполнить только в том случае, если AUTH_TYPE:"NO". Любое значение, которое вы укажете, станет токеном и будет активирована однотокеновая авторизация. |
Однотокеновая авторизация (one-token auth) — это авторизация, при которой существует только один токен, способный пройти авторизацию (его значение необходимо задать в рамках конфигурации ENV).
Пользовательская авторизация - это авторизация, при которой каждому пользователю создается уникальный токен. Информация о пользователях хранится в БД.
Переменные базы данных
Переменные базы данных используются для хранения конфигурационных данных, необходимых для подключения и работы с базой данных при включённой пользовательской авторизации (MTSAI_AUTH = true и AUTH_TYPE = DB). Не используются при ином типе авторизации и отсутствуют по умолчанию в ENV-файле. Добавьте их в файл вручную только в том случае, если вам необходима пользовательская авторизация.
Таблица 9. Переменные базы данных.
| Переменная | Определение |
|---|---|
| USERS_TABLE | Идентификатор таблицы в базе данных PostgreSQL. Требует указания полного имени таблицы. Этот параметр необходим, когда используется пользовательская авторизация для хранения имени таблицы с данными о пользователях. |
| DB_URL | URL для подключения к БД при аутентификации через БД. Заполняется следующим образом: DB_URL=postgresql://${DB_USER}:${DB_PASSWORD}@${DB_HOST}:${DB_PORT}/${DB_NAME} Содержит информацию о БД с пользователями и данные для подключения к этой БД. Не используется при ином типе авторизации, кроме пользовательской. |
| RUN_MIGRATIONS | Для выполнения миграций БД, установите значение этой переменной в значение "1". |
При первом запуске система автоматически создаст необходимую базу данных и таблицу пользователей. Дополнительных действий по инициализации базы данных не требуется.
Переменная настройки генерации модели
Переменная настройки генерации модели устанавливает ограничение при обработке запросов POST/v1/chat/completions.
Таблица 10. Переменная настройки генерации модели.
| Переменная | Определение |
|---|---|
| MAX_N | Устанавливает ограничение для опционального параметра "n", использующегося в запросе POST/v1/chat/completions. Параметр отвечает за то, сколько ответов модель сгенерирует по запросу пользователя. Необходимо установить максимально допустимое значение для параметра "n", чтобы избежать ситуации, когда пользователь задал слишком большой "n" и на один запрос модель генерирует сотни или тысячи ответов. Значение MAX_N по умолчанию: 10. |
Переменные журналирования
Переменные журналирования используются для настройки журналирования API-запросов и определения таблицы БД, куда будет сохранён журнал обработки пользовательских запросов. Все переменные из данного раздела обязательны к заполнению, кроме переменной LOGS.
Таблица 11. Переменные журналирования.
| Переменная | Определение |
|---|---|
| LOGS | Журналирование отключено по умолчанию. Для того чтобы его активировать нужно указать значение переменной True. Если не установить данное значение и не указывать переменную в ENV-файле, то журналирование будет отключено. |
| LOGS_DB_HOST | Адрес сервера PostgreSQL. |
| LOGS_DB_PORT | Порт PostgreSQL, куда будут сохраняться журнал запросов. |
| LOGS_DB_NAME | Имя базы данных, в которую будут сохраняться журнал запросов. |
| LOGS_DB_USERNAME | Имя пользователя для подключения к базе данных. |
| LOGS_DB_PASSWORD | Пароль пользователя для подключения к базе данных. |
Переменные движка ядра vLLM
Таблица 12. Переменные движка ядра.
| Переменная | Определение |
|---|---|
| VLLM_USE_V1 | Включает альфа версию нового ядра vLLM для версии 0.7.2, если VLLM_USE_V1 = 1. Это позволяет увеличить скорость генерации ответа до 1.7х и обеспечивает постоянно включенный prefix caching. Значение переменной по умолчанию: 0. |
| WAIT_VLLM | Включает режим ожидания доступности первого в списке сервиса vLLM. По умолчанию выполняется 5 попыток подключения с таймаутом между попытками в 10 секунд. Используйте эту переменную для случаев, когда приложение запускается в среде без оркестрирования сервисов и нельзя гарантировать старт сервисов vLLM раньше сервиса backend. |
| WAIT_VLLM_ATTEMPTS | Изменяет количество попыток подключения сервиса vLLM. По умолчанию задано 5 попыток подключения. |
| WAIT_VLLM_TIMEOUT | Задает таймаут ожидания между попытками подключения сервиса vLLM. По умолчанию таймаут задан в 10 секунд. |
Примеры заполнения ENV-файла
Однотокеновая авторизация
GPUUTIL: 0.9
MTSAI_AUTH: false
VLLM_API_KEY:<токен авторизации>
USERS_TABLE: <переменная отсутствует>
AUTH_TYPE: <переменная отсутствует>
DB_URL: <переменная отсутствует>
MAX_N: 10
Пользовательская авторизация
GPUUTIL: 0.9
MTSAI_AUTH: true
VLLM_API_KEY: <переменная отсутствует>
USERS_TABLE: <идентификатор таблицы>
AUTH_TYPE: DB
DB_URL:postgresql://${DB_USER}:${DB_PASSWORD}@${DB_HOST}:${DB_PORT}/${DB_NAME}
MAX_N: 10
Отключение журналирования
LOGS – переменная отсутствует в ENV-файле.
LOGS_DB_HOST: <HOST>
LOGS_DB_POST: <PORT>
LOGS_DB_NAME: <DB_NAME>
LOGS_DB_USERNAME: <USERNAME>
LOGS_DB_PASSWORD: <PASSWORD>
Переменные журналирования, кроме LOGS, обязательны к заполнению, даже если вы хотите, чтобы журналирование было отключено. Они необходимы для корректного запуска приложения.
Активное журналирование
LOGS: True
LOGS_DB_HOST: <HOST>
LOGS_DB_POST: <PORT>
LOGS_DB_NAME: <DB_NAME>
LOGS_DB_USERNAME: <USERNAME>
LOGS_DB_PASSWORD: <PASSWORD>
При необходимости, скорректируйте значения переменных в ENV-файле.
После внесения изменений, поместите ENV-файл в ту же директорию, где находится docker-compose.yml.
Запуск Cotype на видеокартах NVIDIA L4
VLLM_WORKER_MULTIPROC_METHOD=spawn
ADDITIONAL_ARGS=--tensor-parallel-size=4
Описание переменных окружения и параметров для запуска Cotype на нескольких видеокартах смотрите в таблице 7.
При запуске на нескольких видеокартах необходимо добавить переменную окружения VLLM_WORKER_MULTIPROC_METHOD=spawn.
Проверьте наличие shm_size >= 10g в docker-compose.yml.
Справочник по API
Справочник по API предоставляет базовую информацию для работы с продуктом и сообщениями в системе.
POST/v1/chat/completions
Основным методом для взаимодействия с моделью является метод POST/v1/chat/completions. Он предназначен для отправки списка сообщений в формате чата. На основе полученных входных данных, модель сгенерирует ответ на запрос пользователя. Метод может использоваться как для ведения диалогов, состоящих из нескольких последовательных сообщений, так и для выполнения задач, требующих однократного обращения без продолжительного разговора.
Тип запроса: POST
Запрос: https://IP_Address/v1/chat/completions
Где "IP_Address" необходимо заменить на IP-адрес вашей машины, если модель развёрнута внутри вашего контура. Если вы обращаетесь к демо-стенду внутри контура MWS AI, то адрес стенда будет передан вам отдельно.
Например: https://1.1.1.1:8000/v1/chat/completions
Таблица 13. Параметры запроса POST/v1/chat/completions
| Имя | Тип данных | Значение | Описание |
|---|---|---|---|
| messages (обязательный) | string | Текстовый ответ | Одно сообщение или список из нескольких сообщений в формате чата, на основе которых, модель должна сгенерировать ответ. |
| model (обязательный) | string | ID | ID модели, к которой вы обращаетесь. Вы можете узнать список доступных вам моделей через запрос GET/v1/models. Подробнее в разделе GET/v1/models. |
| temperature | float | Диапазон температуры — от 0 до 2. Рекомендованное значение: 0.5 | Более низкие значения температуры приводят к более последовательным результатам (например, 0.2), в то время как более высокие значения генерируют более разнообразные и творческие результаты (например, 1.0). |
| top_p | integer | Диапазон — от 0 до 1. | Чем ниже значение атрибута, тем более популярные и часто встречающиеся токены модель будет использовать для формирования ответа. Рекомендуем изменять или этот атрибут, или temperature, но не оба сразу. |
| max_tokens | integer | Натуральное число, больше 0. | Максимальное количество токенов, которые могут быть сгенерированы в ответ на запрос пользователя. Это позволяет регулировать длину ответа. |
| n | integer | Натуральное число больше 0. По умолчанию: 1. | Количество ответов, которые модель сгенерирует. |
| stream | boolean | True/False. По умолчанию: false. | Если установить значение true, ответ модели будет возвращаться не целиком сразу, а итеративно, по мере его формирования моделью. |
| stream_options | object or null |  |
Параметры для потокового ответа. Устанавливайте только при установке stream: true. |
| include_usage | boolean |  |
Если установлен в true, то будет добавлен новый информационный фрагмент перед последним фрагментом [DONE]. Поле usage в этом фрагменте показывает статистику использования токенов для всего запроса, а поле choices всегда будет пустым массивом. |
| frequency_penalty | integer | Натуральное число от -2 до 2. | Штраф за частоту — число между -2.0 и 2.0. Положительные значения штрафуют новые токены, на основе их текущей частоты в тексте, снижая вероятность того, что модель повторит одну и ту же строку. |
| presence_penalty | integer | Натуральное число от -2 до 2. | Положительные значения накладывают штраф на новые токены в зависимости от того, появляются ли они в тексте до сих пор, увеличивая вероятность того, что модель будет говорить о новых темах. |
| logit_bias | map | По умолчанию: null | Позволяет изменять вероятность появления указанных токенов в генерации. Принимает объект JSON, который сопоставляет токены (указанные по их идентификатору токена в токенизаторе) со связанным значением отклонения от -100 до 100. logit_bias позволяет запретить модели использовать некоторые ID токенов. Чем ближе значение параметра к -100, тем больше вероятность, что токен будет заблокирован моделью. Чем ближе значение параметра к + 100, тем больше вероятность что токен будет использован моделью. |
| logprobs | boolean or null | По умолчанию: false | Задает возвращать ли логарифмические вероятности выходных токенов или нет. Если true, возвращает логарифмические вероятности каждого выходного токена, возвращенного в содержимом сообщения. |
| top_logprobs | integer or null | Целое число от 0 до 20, регулирующее количество наиболее вероятных токенов с их логарифмическими вероятностями, которые будут возвращены для каждого генерируемого токена. Если используется этот параметр, то logprobs должен быть установлен в значение true. |
|
| stop | string/array/null | Список строк, после которых останавливается генерация. Эти строки не будут включены в ответ. | |
| parallel_tool_calls | boolean | По умолчанию: true | Определяет следует ли включать параллельный вызов функций/тулов. |
| tool_choice | string | Определяет как модель выбирает tools. Значения - auto, none, required, или задайте функцию. | |
| tools | array | Список функций (тулов) с описаниями и аргументами, среди которых модель может выбрать необходимые тулы и извлечь значения аргументов из промпта для использования приложением. Подробнее про добавление функции смотрите в разделе Добавление функции function calling (tool use) через дополнительные аргументы. | |
| function | object | Вызываемая функция. | |
| description | string | Описание функции, включая инструкцию, когда и как ее вызвать. | |
| name | string | Название функции. | |
| parameters | object | Параметры функции в json. | |
| strict | boolean or null | Задает следует ли включать строгое соблюдение схемы при генерации вызова функции. Если установлено значение true, модель будет точно соответствовать схеме, определенной в поле parameters. Если значение strict равно true, поддерживается только подмножество схем JSON. |
|
| type | string | tool тип, например функция. | |
| user | string | Уникальный идентификатор, представляющий вашего конечного пользователя, который может помочь отслеживать и обнаруживать злоупотребления. |
Использование запроса POST/v1/chat/completions
- Укажите Bearer Token.
При активной однотокеновой авторизации токен одинаковый у всех пользователей. При пользовательской авторизации выдаются индивидуальные токены. Подробнее о типах авторизации и их настройке смотрите в разделе Переменные авторизации -
Заполните тело запроса.
Обязательные параметры:modelиmessages. Вmodelнеобходимо указать ID вашей модели. Получить ID модели можно с помощью запросаGET /v1/models, подробное описание смотрите в разделе GET /v1/models.
Вmessagesнеобходимо указать "role" и "content". У атрибута "role" может быть одно из двух значений:- "system" - обозначение для системного промпта, который задает роль модели, например, что модель должна отвечать как учитель или как политик. Необязательный атрибут;
- "user" - обозначение пользовательского промпта, который содержит ваш вопрос или ваши инструкции для модели. Обязательный атрибут.
В параметр "content" запишите ваш системный или пользовательский промпт.
{ "model": "//ID вашей модели", "messages": [ { "role": "system", "content": "Отвечай как экскурсовод" }, { "role": "user", "content": "Расскажи мне о Москве в 1 предложении." }] }Пример заполнения представлен ниже.
{ "model": "cotype_pro_2", "messages": [ { "role": "system", "content": "Отвечай как экскурсовод" }, { "role": "user", "content": "Расскажи мне о Москве в 1 предложении." }] }Пример curl-запроса для выполнения запроса из командной строки:
curl https://{url}/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer Token" \ -d '{ "model": "cotype_pro_2", "messages": [ { "role": "system", "content": "Отвечай как экскурсовод" }, { "role": "user", "content": " Расскажи мне о Москве в 1 предложении." }] }'
Результат выполнения запроса POST/v1/chat/completions
Результат успешного запроса:
{
"id": "chatcmpl-db457e150dcb4c358fd2bab38db5d4f6",
"object": "chat.completion",
"created": 1748963043,
"model": "cotype_pro_2",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "Москва, столица России, - это тысячелетний город с богатой историей и архитектурой, где древнерусские храмы и кремли, таких как Красная площадь и Московский Кремль, соседствуют с современными небоскребами и шумными улицами, создавая уникальный контраст между прошлым и настоящим."
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 89,
"total_tokens": 193,
"completion_tokens": 104
},
"prompt_logprobs": null
}Таблица 14. Параметры ответа на запрос POST/v1/chat/completions
| Имя | Тип данных | Пример значение | Описание |
|---|---|---|---|
| id | string | cmpl-e263c7d6179a43e98b2ca9580b57e4f6 | Идентификатор запроса. |
| object | string | chat.completion | Тип объект. |
| created | integer | 1748963043 | Временная метка UNIX (в секундах), отмечающая дату и время, когда был создан запрос. |
| model | string | cotype_pro_2 | ID модели, к которой вы обращались и которая ответила на ваш запрос. |
| choices | array | Список вариантов завершения чата. | |
| index | integer | 0 | Индекс выбора в списке вариантов. |
| message | object | Сгенерированное моделью сообщение. | |
| role | string | assistant | Роль автора сообщения. |
| content | string or null | Москва, столица России, - это тысячелетний город с богатой историей и архитектурой, где древнерусские храмы и кремли, таких как Красная площадь и Московский Кремль, соседствуют с современными небоскребами и шумными улицами, создавая уникальный контраст между прошлым и настоящим. | Содержание сообщения. |
| tool_calls | array | [] | Вызовы тулов (функций), генерируемые моделью. |
| logprobs | object or null | null | Логирование информации о вероятности выбора. |
| finish_reason | string or null | stop | Причина, по которой модель прекратила генерировать ответы. stop - если модель достигла естественной точки остановки или предоставленной последовательности остановки. length - если было достигнуто максимальное количество токенов, указанное в запросе. content_filter - если контент был пропущен из-за флага из фильтров контента. tool_calls - если модель вызвала tool, или если модель вызвала функцию. |
| stop_reason | string or null | Аналогична finish_reason. |
|
| usage | object or null |  |
Статистика по токенам в вашем запросе. Это поле присутствует в ответе на запрос, если при установке stream_options: {"include_usage": true} в запросе. Если поле присутствует, поле содержит нулевое значение, за исключением последнего фрагмента, который содержит статистику использования токена для всего запроса. |
| prompt_tokens | integer | 39 | Количество токенов в запросе. |
| completion_tokens | integer | 91 | Количество сгенерированных моделью токенов. |
| total_tokens | integer | 130 | Cумма токенов в запросе и сгенерированных токенов. |
| prompt_logprobs | object or null | null | Логирование информации о промпте. |
Для продолжения общения с моделью в рамках текущего диалога необходимо дополнить ваш предыдущий запрос ответом модели, а также добавить новое сообщение от лица пользователя. Атрибут role показывает, кто является автором сообщения в диалоге. Assistant — ответ модели, user — сообщение пользователя.
Пример тела запроса:
{
"model": "//имя вашей модели",
"messages": [
{
"role": "system","content": "Отвечай как экскурсовод"
},
{
"role": "user", "content": "Расскажи мне о Москве в 1 предложении."
},
{
"role": "assistant", "content": "Москва - это столица России, древний и современный город, объединяющий богатую историю и культуру, архитектурные шедевры, таких как Кремль и храм Василия Блаженного, с динамичной городской жизнью, современными технологиями и инфраструктурой, а также уникальной атмосферой, которая сочетает в себе традиции и инновации."
},
{
"role": "user", "content": "Расскажи мне более подробно о Кремле."
}]
}Модель сформирует ответ на ваш запрос с учётом контекста диалога. В данном примере расскажет именно о московском Кремле, а не о казанском или новгородском.
Пример выполнения запроса POST/v1/chat/completions с функцией tool calling
import requests
import json
def get_weather(location: str, unit: str):
return f"Получить погоду для {location} в {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Определить текущую погоду в городе",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "Город или поселок, например, 'Москва'"},
"unit": {"type": "string", "enum": ["цельсии", "фаренгейты"]}
},
"required": ["location", "unit"]
}
}
}]
# URL API
url = "http://localhost:8000/v1/chat/completions"
# Заголовки запроса
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer dummy"
}
# Тело запроса
data = {
"model": "your-model-name", # Замените на имя вашей модели
"messages": [{"role": "user", "content": "Как тепло сейчас в Санкт-Петербурге?"}],
"tools": tools,
"tool_choice": "auto"
}
# Отправка POST-запроса
response = requests.post(url, headers=headers, json=data)
# Проверка статуса ответа
if response.status_code == 200:
response_data = response.json()
tool_call = response_data['choices'][0]['message']['tool_calls'][0]['function']
print(f"Function called: {tool_call['name']}")
print(f"Arguments: {tool_call['arguments']}")
print(f"Result: {get_weather(**json.loads(tool_call['arguments']))}")
else:
print(f"Error: {response.status_code}")
print(response.text)Ответ от модели:
{
'id': 'chatcmpl-080f745514ee4e27bffca4e567ba3c4a',
'object': 'chat.completion',
'created': 1741944362,
'model': 'cotype',
'choices': [{
'index': 0,
'message': {
'role': 'assistant',
'content': None,
'tool_calls': [{
'id': 'chatcmpl-tool-8e49f569510b4cf6afd5524aee967647',
'type': 'function',
'function': {
'name': 'get_weather',
'arguments': '{"location": "Санкт-Петербург", "unit": "цельсии"}'
}
}]
},
'logprobs': None,
'finish_reason': 'tool_calls',
'stop_reason': None
}],
'usage': {
'prompt_tokens': 261,
'total_tokens': 294,
'completion_tokens': 33,
'prompt_tokens_details': None
},
'prompt_logprobs': None
}GET/v1/models
Метод для получения списка доступных вам моделей.
Тип запроса: GET
Запрос:
https://IP_Address/v1/modelsгде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/v1/modelsПример curl-запроса для выполнения запроса из командной строки:
curl -X 'GET' \ 'https://{url}/v1/models' \
-H 'accept: application/json'
-H 'Authorization: Bearer Token' \Пример ответа на запрос GET/v1/models:
{
"object": "list",
"data": [
{
"id": "cotype_pro_2",
"object": "model",
"created": 1748228864,
"owned_by": "vLLM",
"root": "/data/models/infer/model",
"parent": null,
"permission": [
{
"id": "modelperm-5f9920eb9187466b998ccccd208c9f95",
"object": "model_permission",
"created": 1748228864,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}В результате выполнения запроса, вы получите список доступных вам моделей. Для обращения к модели скопируйте "id" - уникальный идентификатор модели в теле ответа на запрос. Затем используйте скопированный ID в запросе POST/v1/chat/completions в параметре model.
GET/health
Назначение: Запрос проверяет работоспособность модели. Если модель работоспособна, будет получен ответ [200 OK]. В случае если сервис недоступен по какой-либо причине, ответ не будет получен.
Тип запроса: GET
Запрос:
https://IP_Address/healthГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/healthПример curl-запроса для выполнения запроса из командной строки:
curl -X 'GET' \
'https://{url}/health' \
-H 'accept: application/json'POST/v1/completions
Назначение: Система дополняет и продолжает промпт пользователя. Не подходит для общения в чатовом режиме.
Тип запроса: POST
Запрос:
https://{IP-адрес}/v1/completionsГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/v1/completionsТаблица 15. Параметры запроса POST/v1/completions
| Имя | Тип данных | Значение | Описание |
|---|---|---|---|
| prompt (обязательный) | string or array | Запрос(ы) для генерации дополнений, закодированные как строка, массив строк, массив токенов или массив массивов токенов. Обратите внимание, что <¦endoftext¦> — это разделитель документов, который модель видит во время обучения, поэтому, если запрос не указан, модель будет генерировать так, как будто с начала нового документа. |
|
| model (обязательный) | string | ID | ID модели, к которой вы обращаетесь. |
| temperature | number or null | Диапазон температуры — от 0 до 2. По умолчанию: 1. | Задает температуру выборки, от 0 до 2. Более высокие значения, такие как 0.8, сделают вывод более случайным, а более низкие значения, такие как 0.2, сделают его более сфокусированным и детерминированным. Обычно рекомендуется изменять это значение или top_p параметр, но не оба. |
| top_p | number or null | Диапазон — от 0 до 1. По умолчанию: 1. | Чем ниже значение атрибута, тем более популярные и часто встречающиеся токены модель будет использовать для формирования ответа. Рекомендуем изменять или этот атрибут, или temperature, но не оба сразу. |
| max_tokens | integer | Натуральное число, больше 0. По умолчанию: 16. | Максимальное количество токенов, которые могут быть сгенерированы в ответ на запрос пользователя. Это позволяет регулировать длину ответа. |
| n | integer or null | Натуральное число больше 0. По умолчанию: 1. | Количество ответов, которые модель сгенерирует. |
| stream | boolean or null | True/False. По умолчанию: false. | Если установить значение true, ответ модели будет возвращаться не целиком сразу, а итеративно, по мере его формирования моделью. |
| stream_options | object or null |  |
Параметры для потокового ответа. Устанавливайте только при установке stream: true. |
| include_usage | boolean | Если установлено, дополнительный фрагмент будет передан перед сообщением data: [DONE]. Поле usage в этом фрагменте показывает статистику использования токена для всего запроса, а поле choices всегда будет пустым массивом. Все остальные фрагменты также будут включать поле usage, но с "null" значением. |
|
| frequency_penalty | integer | Натуральное число от -2 до 2. | Штраф за частоту — число между -2.0 и 2.0. Положительные значения штрафуют новые токены, на основе их текущей частоты в тексте, снижая вероятность того, что модель повторит одну и ту же строку. |
| presence_penalty | integer | Натуральное число от -2 до 2. По умолчанию: 0. | Положительные значения накладывают штраф на новые токены в зависимости от того, появляются ли они в тексте до сих пор, увеличивая вероятность того, что модель будет говорить о новых темах. |
| logit_bias | map | По умолчанию: null. | Изменяет вероятность появления указанных токенов в завершении. Принимает объект JSON, который сопоставляет токены (указанные по их идентификатору токена в токенизаторе) со связанным значением смещения от -100 до 100. |
| best_of | integer or null | По умолчанию: 1. | Генерирует best_of завершений на стороне сервера и возвращает «лучшее» (то, которое имеет наибольшую вероятность логарифма на токен). Результаты не могут быть переданы потоком. При использовании с n, best_of управляет количеством кандидатов на завершение, а n указывает, сколько возвращать. best_of должно быть больше n. |
| echo | boolean or null | По умолчанию: false. | Повторяет промпт в дополнение к завершению. |
| logprobs | integer or null | По умолчанию: null. | Включает логарифмические вероятности на logprobs наиболее вероятных выходных токенах, а также выбранные токены. Например, если logprobs равен 5, API вернет список из 5 наиболее вероятных токенов. |
| seed | integer or null | Если параметр задан, система приложит все усилия для детерминированной выборки, чтобы повторные запросы с тем же начальным значением и параметрами возвращали тот же результат. | |
| stop | string/array/null | До 4 последовательностей, при которых API прекратит генерацию дальнейших токенов. | |
| suffix | string or null | По умолчанию: null. | Суффикс, который следует после завершения вставленного текста. |
| user | string | Уникальный идентификатор, представляющий вашего конечного пользователя, который может помочь отслеживать и обнаруживать злоупотребления. |
Использование запроса POST/v1/completions
-
Укажите Bearer Token.
При активной однотокеновой авторизации токен одинаковый у всех пользователей. При пользовательской авторизации выдаются индивидуальные токены. Подробнее о типах авторизации и их настройке в разделе Переменные авторизации.
-
Заполните тело запроса.
Обязательные параметры:modelиprompt. Вmodelнеобходимо указать ID вашей модели. Получить ID модели можно с помощью запросаGET/v1/models, подробное описание смотрите в разделе GET/v1/models.
Пример curl-запроса для выполнения запроса из командной строки:curl -X 'POST' \ 'https://{IP-адрес}/v1/completions' \ -H 'accept: application/json' curl https://{IP-адрес}/v1/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer Token" \ -d '{"model": "cotype_pro_2", "prompt": "Тестовый запрос"}'Результат выполнения запроса POST/v1/completions
Результат успешного запроса:
{
"id": "cmpl-b1e39b7c457f46e2af97b47e921cf64c",
"object": "text_completion",
"created": 1740518640,
"model": "cotype_pro_2",
"choices": [
{
"index": 0,
"text": "! Как дела?\r",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 116,
"total_tokens": 121,
"completion_tokens": 5,
"prompt_tokens_details": null
}
}Таблица 16. Параметры ответа на запрос POST/v1/completions
| Имя | Тип данных | Пример значения | Описание |
|---|---|---|---|
| id | string | cmpl-b1e39b7c457f46e2af97b47e921cf64c | Идентификатор запроса. |
| object | string | text.completion | Тип объект. |
| created | integer | 1740518640 | Временная метка UNIX (в секундах), отмечающая дату и время, когда был создан запрос. |
| model | string | cotype_pro_2 | ID модели, к которой вы обращались и, которая ответила на ваш запрос. |
| choices | array | Список вариантов завершения чата. | |
| index | integer | 0 | Индекс выбора в списке вариантов. |
| text | string | Сгенерированное моделью сообщение. | |
| logprobs | object or null | null | Логирование информации о вероятности выбора. |
| finish_reason | string | stop | Причина, по которой модель прекратила генерировать ответы.stop - если модель достигла естественной точки остановки или предоставленной последовательности остановки. length - если было достигнуто максимальное количество токенов, указанное в запросе. content_filter - если контент был пропущен из-за флага из фильтров контента. tool_calls - если модель вызвала инструмент, или если модель вызвала функцию. |
| stop_reason | string or null | Аналогична finish_reason. |
|
| prompt_logprobs | object or null | null | Логирование информации о промпте. |
| usage | object or null | "prompt_tokens": 116, |
Статистика запроса на завершение. |
| prompt_tokens | integer | 39 | Количество токенов в промпте. |
| completion_tokens | integer | 91 | Количество сгенерированных моделью токенов. |
| total_tokens | integer | 130 | Cумма токенов в запросе и сгенерированных токенов. |
POST/v1/embeddings
Назначение: Запрос трансформирует отправленный текст в эмбеддинги. Предназначен для представления текста в векторном виде.
Тип запроса: POST
Запрос:
https://IP_Address/v1/embeddingsГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/v1/embeddingsПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{IP-адрес}/v1/embeddings' \
-H 'accept: application/json'
curl https://{IP-адрес}/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer Token" \
-d '{"text": ["Тестовый запрос"]}'Пример ответа на запрос POST/v1/embeddings:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [0.8983038067817688,
0.09742391109466553,
-0.9155033230781555,
…
]
}],
"model": "mtsai-chat-embeddings",
"usage": {
"prompt_tokens": 6,
"total_tokens": 6
}
}POST/token
Назначение: Получение токена доступа для работы с API.
Тип запроса: POST
Запрос:
https://IP_Address/tokenГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/tokenПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/token' \
-H 'accept: application/json' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'username=your.email@example.ru&password=your_password'Пример ответа на запрос:
{
"access_token": "string",
"token_type": "string"
}GET/users/me
Назначение: Получение информации о текущем авторизованном пользователе.
Тип запроса: GET
Запрос:
https://IP_Address/users/me Где IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/users/me Пример curl-запроса для выполнения запроса из командной строки:
curl -X 'GET' \
'https://{url}/users/me' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_TOKEN' Пример ответа на запрос:
{
"token": "your_token",
"email": "your_name@example.ru",
"expiration_date": "2025-03-24",
"disabled": false,
"privileged": false
} GET/get_user_info
Назначение: Получение информации о пользователе по email (только для администраторов).
Тип запроса: GET
Запрос:
https://IP_Address/get_user_info?email=user@example.ru Где IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/get_user_info?email=user@example.ru Пример curl-запроса для выполнения запроса из командной строки:
curl -X 'GET' \
'https://{url}/get_user_info?email=user%40example.ru' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN' Пример ответа на запрос:
{
"token": "your_token",
"email": "user@example.ru",
"expiration_date": "2025-12-09",
"disabled": false,
"privileged": false
} POST/create_user
Назначение: Создание нового пользователя (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/create_userГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/create_userПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/create_user' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'email=new.user@example.ru&password=user_password&expire=28&privileged=false'Пример ответа на запрос:
{
"token": "admin_token",
"email": "new.user@example.ru",
"expiration_date": "2025-03-27",
"disabled": false,
"privileged": true
}POST/disable_by_email
Назначение : Блокировка пользователя по email (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/disable_by_emailГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/disable_by_email Пример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/disable_by_email' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'email=user@example.ru'Пример ответа на запрос:
Start disabling:POST/disable_by_token
Назначение: Блокировка пользователя по токену (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/disable_by_tokenГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/disable_by_tokenПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/disable_by_token' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'token=user_token'Пример ответа на запрос:
Start disabling:POST/disable_all_expired
Назначение: Блокировка всех пользователей с истекшим сроком действия (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/disable_all_expiredГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/disable_all_expired Пример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/disable_all_expired' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN'Пример ответа на запрос:
Start disabling:
Disable user1 user1@example.ru with
token user1_token
Disable user2 user2@example.ru with
token user2_tokenPOST/delete_by_email
Назначение: Удаление пользователя по email (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/delete_by_emailГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/delete_by_emailПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/delete_by_email' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'email=user@example.ru'Пример ответа на запрос:
Start deletion:
0 users with email user@example.ru were deletedPOST/delete_by_token
Назначение: Удаление пользователя по токену (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/delete_by_token Где IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/delete_by_tokenПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/delete_by_token' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'token=user_token'Пример ответа на запрос:
Start deletion:
0 users with token user_token were deletedPOST/delete_all_disabled
Назначение: Удаление всех заблокированных пользователей (только для администраторов).
Тип запроса: POST
Запрос:
https://IP_Address/delete_all_disabledГде IP_Address необходимо заменить на IP-адрес вашей машины или адрес демо-стенда. Например:
https://1.1.1.1:8000/delete_all_disabledПример curl-запроса для выполнения запроса из командной строки:
curl -X 'POST' \
'https://{url}/delete_all_disabled' \
-H 'accept: application/json' \
-H 'Authorization: Bearer ADMIN_TOKEN'Пример ответа на запрос:
Start deletion:
Delete user1 user1@example.ru with
token user1_token
Delete user2 user2@example.ru with
token user2_tokenЖурналирование API-запросов
Следующие API-запросы журналируются в БД:
POST/{url}/v1/chat/completions;GET/{url}/v1/models;POST/{url}/v1/completions;POST/{url}/v1/embeddings.
Информация о запросах сохраняется в БД, которая была указана в переменных ENV-файла. Можно ознакомиться с запросами пользователей, увидеть ответы системы, длительность обработки запросов и код ответа. При активной пользовательской авторизации сохраняется логин пользователя, отправившего запрос. При однотокеновой авторизации отсутствует возможность идентифицировать отправителя запроса.
Таблица 17. Структура таблицы БД с журналом запросов.
| Поле | Описание поля | Пример значения |
|---|---|---|
| id | Идентификатор записи о API-запросе. | 12273 |
| user | IP-адрес пользователя, отправившего запрос. | 10.216.28.2 |
| username | Имя пользователя, отправившего запрос. Актуально при активной пользовательской авторизации. | a.antonov@mts.ai |
| type | Тип запроса, отправленного пользователем. | POST /v1/chat/completions |
| request | Тело запроса. |  |
| request_dt | Время получения запроса. | 2024-10-08 08:02:28.283771 |
| response | Ответ системы на запрос. | 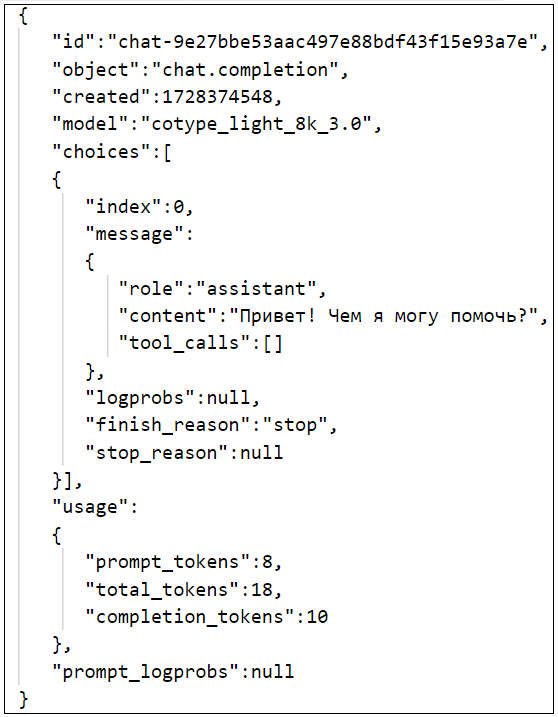 |
| response_dt | Время ответа на запрос. | 2024-10-08 01:02:41.369049 |
| status_code | Код, с которым система ответила на запрос. | 200 |
| config_id | При запуске система сохраняет настройки, с которыми она была запущена, в отдельную таблицу. Поле представляет собой внешний ключ с ссылкой на таблицу, в которую были сохранены эти настройки. | 9 |
Также при каждом запуске система сохраняет настройки, с которыми она была запущена. Сохранение производится в отдельную таблицу, связанную с таблицей выше.
Работа с чат-интерфейсом
Для чат-интерфейса используется open source решение "NextChat".
Установка
- Скачайте образ UI из Artifactory. Ссылка для скачивания образа будет передана отдельно.
- Ознакомьтесь с содержимым ENV-файла, который передан вместе с docker-compose файлом. ENV-файл содержит значения переменных окружения.
Таблица 18. Переменные ENV-файла.
| Переменная | Определение |
|---|---|
| BASE_URL | Адрес модели, к которой будет обращаться UI. |
| CUSTOM_MODELS | Список доступных моделей. Пользователи могут переключаться между моделями в настройках и выбирать к какой модели обратиться. |
| DEFAULT_MODEL | Здесь необходимо указать одну из моделей, внесённую ранее в CUSTOM_MODELS. К данной модели UI будет обращаться по умолчанию, пока пользователь не выберет в настройках иную модель. |
| CODE (опциональный параметр) | Access-code, который пользователь может ввести вместо токена для авторизации в чат-интерфейсе. |
| OPENAI_API_KEY (опциональный параметр) | Токен, с которым чат-интерфейс будет обращаться к LLM, если пользователь указал только access code. |
-
Заполните ENV-файл следующим образом:
CUSTOM_MODELS: -all,+cotype_pro_2DEFAULT_MODEL: cotype_pro_2OPENAI_API_KEY: <токен для отправки запросов к API>
В переменной
CUSTOM MODELSможет быть указано несколько моделей. Проверьте заполнение, должно быть аналогично примеру: перед моделью от MWS AI проставлен знак "+", перед all и остальными названиями моделей указан знак "-". -
Для запуска UI, добавьте в docker-compose файл сервис ui, как показано ниже:

-
Запустите контейнер с помощью команды:
docker compose up -dУбедитесь, что у вас установлен Docker Compose. UI будет доступен на порте 3000.
Приложение 1. Описание возвращаемых ошибок при работе с методами API
Все запросы
401 — пользователь указал некорректный токен. Code 401: "UnauthorizedError: Wrong token"
403 — ошибка прав доступа. Для методов управления правом доступа пользователя. Например, когда пользователь пытается выполнить действие, доступное только администратору.
405 — метод не поддерживается. Code 405: "Method Not Allowed".
422 — ошибка, возникающая при некорректном по структуре запросе. Code 422: "Unprocessable Entity". Относится к методам с POST-запросом.
500 — непредвиденная ошибка. Code 500: "Internal Server Error".
Запрос POST/v1/chat/completions
503 — ошибка, возникающая в случае недоступности сервиса "Цензор". Code 503 — "The server was unable to complete your request. Please try again later".
Атрибут: model, обязательный
-
Пользователь ввёл некорректный ID модели, система не смогла обнаружить модель с таким ID.
Пример ответа 404:
"The model "model" does not exist."Где "model" - тот ID модели, который указал пользователь.
-
В запросе отсутствует атрибут "model".
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'missing','loc': ('body', 'model'),'msg': 'Field required','input':{'messages': "[{'role': 'system','content':'promt'},{'role': 'user','content': 'promt'}]}}]", "type": "BadRequestError", "param": null, "code": 400 }
Атрибут: messages, обязательный
-
Пользователь ввёл слишком длинный промт.
Пример ответа 404:
"This model's maximum context length is X tokens. However, you requested N tokens in the messages, Please reduce the length of the messages."Где
N- количество токенов в промпте ("prompt_tokens"),
X- максимально допустимое количество токенов в промпте у модели, к которой пользователь обратился. -
В запросе отсутствует атрибут "messages".
Пример ответа 404:
{ "object": "error", "message": "[{'type': 'missing','loc': ('body', 'messages'),'msg': 'Field required', 'input': {'model':'cotype_pro_2.0'}}]", "type": "BadRequestError", "param": null, "code": 400 }Атрибут: temperature, опциональный
-
Значение, введенное пользователем, не является числом.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'float_parsing','loc': ('body', 'temperature'),'msg': 'Input should be a valid number, unable to parse string as a number','input': 'gh'}]", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввел число, но оно отрицательное.
Пример ответа 400:
{ "object": "error", "message": "temperature must be non-negative, got -5.0.", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввел число, но оно больше 2.
Пример ответа 400:
{ "object": "error", "message": "temperature must be in the range from 0 to 2, got 3.", "type": "BadRequestError", "param": null, "code": 400 }
Атрибут: top_p, опциональный
-
Значение, введенное пользователем, не является числом.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'float_parsing','loc': ('body', 'top_p'),'msg': 'Input should be a valid number, unable to parse string as a number', 'input': 'gh'}]", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввёл число, но оно находится вне диапазона от 0 до 1.
Пример ответа 400:
{ "object": "error", "message": "top_p must be in (0, 1], got -1.0.", "type": "BadRequestError", "param": null, "code": 400 }
Атрибут: max_tokens, опциональный
-
Значение, введенное пользователем, не является числом.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'int_parsing','loc': ('body', 'max_tokens'),'msg': 'Input should be a valid integer, unable to parse string as an integer', 'input': 'gh'}]", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввёл отрицательное число.
Пример ответа 400:
{ "object": "error", "message": "max_tokens must be at least 1, got -1.", "type": "BadRequestError", "param": null, "code": 400 }где -1 - это число, введенное пользователем, может быть любое отрицательное.
-
Пользователь ввёл дробь, а не целое число.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'int_from_float', 'loc': ('body', 'max_tokens'),'msg': 'Input should be a valid integer, got a number with a fractional part','input': 1.5}]", "type": "BadRequestError", "param": null, "code": 400 } -
Если значение атрибута превышает текущее ограничение модели.
Пример ответа 400:
{ "object": "error", "message": "This model's maximum context length is 32768 tokens. However, you requested 100000347 tokens (347 in the messages, 100000000 in the completion). Please reduce the length of the messages or completion.", "type": "BadRequestError", "param": null, "code": 400 }Где
X- длина контекстного окна модели, меняется в зависимости от развернутой модели,
100000347 - введенное пользователем значение max_tokens,
347 - длина промта в токенах. Числа указаны исключительно в качестве примера.
Атрибут: n, опциональный
-
Значение, введенное пользователем, не является числом. Пользователь ввел число, которое не является натуральным.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'int_parsing', 'loc': ('body', 'n'), 'msg': 'Input should be a valid integer, unable to parse string as an integer', 'input': 'gh'}]", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввёл отрицательное число.
Пример ответа 400:
{ "object": "error", "message": "n must be at least 1, got -1.", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввёл дробь, а не целое число.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'int_from_float','loc': ('body', 'n'),'msg': 'Input should be a valid integer, got a number with a fractional part','input': 1.5}]", "type": "BadRequestError", "param": null, "code": 400 } -
Значение n не должно быть больше 10.
Пример ответа 400:
{ "object": "error", "message": "n must be in the range from 1 to 10, got 23.", "type": "BadRequestError", "param": null, "code": 400 }
Атрибут: stream, опциональный
Тип атрибута - boolean. Пользователь ввёл значение, отличное от True/False.
Пример ответа 400:
{
"object": "error",
"message": "[{'type': 'bool_type','loc': ('body', 'stream'),'msg': 'Input should be a valid boolean','input': 1.5}]",
"type": "BadRequestError",
"param": null,
"code": 400
}Атрибут: frequency_penalty, опциональный
-
Значение, введенное пользователем, не является числом.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'float_parsing','loc': ('body', 'frequency_penalty'),'msg': 'Input should be a valid number, unable to parse string as a number','input': 'gh'}]", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввел число, но она находится вне диапазона от -2 до 2.
Пример ответа 400:
{ "object": "error", "message": "frequency_penalty must be in [-2, 2], got -3.0.", "type": "BadRequestError", "param": null, "code": 400 }Где -3.0 - значение, введенное пользователем.
Атрибут: presence_penalty, опциональный
-
Значение, введенное пользователем, не является числом.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'float_parsing','loc': ('body', 'presence_penalty'),'msg': 'Input should be a valid number, unable to parse string as a number', 'input': 'gh'}]", "type": "BadRequestError", "param": null, "code": 400 } -
Пользователь ввел число, но она находится вне диапазона от -2 до 2.
Пример ответа 400:
{ "object": "error", "message": "presence_penalty must be in [-2, 2], got -3.0.", "type": "BadRequestError", "param": null, "code": 400 }Где -3.0 - значение, введенное пользователем.
Нераспознанный атрибут
Пользователь прислал не json в теле запроса, а какой-то иной формат данных.
Пример ответа 400:
{
"object": "error",
"message": "[{'type': 'json_invalid','loc': ('body', 65), 'msg': 'JSON decode error', 'input': {}, 'ctx': {'error': 'Expecting value'}}]",
"type": "BadRequestError",
"param": null,
"code": 400
}Запрос GET/v1/models
Ошибки, характерные только для данного запроса, отсутствуют.
Запрос POST/v1/completions
503 — ошибка, возникающая в случае недоступности сервиса "Цензор". Code 503 — "The server was unable to complete your request. Please try again later".
Атрибут: prompt, обязательный
-
Пользователь ввёл слишком длинный промт.
Пример ответа 400:
"This model's maximum context length is X tokens. However, you requested N tokens in the messages, Please reduce the length of the messages."Где
N- количество токенов в промпте ("prompt_tokens"),
X- максимально допустимое количество токенов в промпте у модели, к которой пользователь обратился. -
В запросе отсутствует атрибут "messages".
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'missing','loc': ('body', 'prompt'),'msg': 'Field required','input': {'model': 'model_name}}]", "type": "BadRequestError", "param": null, "code": 400 }
Атрибут: model, обязательный
-
Пользователь ввёл некорректный ID модели, система не смогла обнаружить модель с таким ID.
Пример ответа 400:
"The model "model" does not exist."Где "model" - тот ID модели, который указал пользователь.
-
В запросе отсутствует атрибут.
Пример ответа 400:
{ "object": "error", "message": "[{'type': 'missing','loc': ('body', 'model'), 'msg': 'Field required', 'input': {'messages': [{'role': 'system', 'content': 'promt'}, {'role': 'user', 'content': 'promt'}]}}]", "type": "BadRequestError", "param": null, "code": 400 }
